Loss function, in essence is to measure how badly the machine learning algorithm screwed up the prediction quantitatively.
Definition from Stanford open course is

To have a concrete feeling, the below example from this blog post is more straightforward.
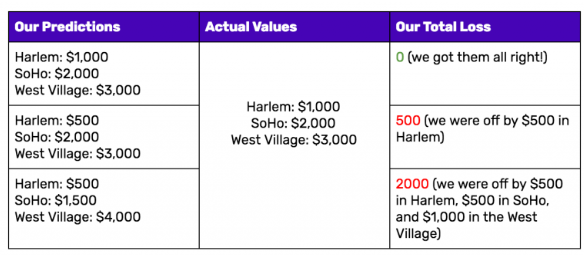
There are multiple ways to measure the loss, mean squared error (MSE), likelihood loss, log loss(cross entropy loss) etc.
def MSE(y_predicted, y):
squared_error = (y_predicted - y) ** 2
sum_squared_error = np.sum(squared_error)
mse = sum_squared_error / y.size
return(mse)
likelihood loss is computed in a way as below, if the predicated probabilities is [0.4, 0.6, 0.9, 0.1], while the truth labels are [0, 1, 1, 0]. The likelihood loss would be computed as (0.6) * (0.6) * (0.9) * (0.9) = 0.2916. Since the model outputs probabilities for TRUE (or 1) only, when the ground truth label is 0 we take (1-p) as the probability.
log loss or cross entropy loss is more complicated to understand.
to continue the cross-entropy loss
