It’s all same, daunting image or tirade long text, once they are converted to digital forms, Tensorflow ML algorithm can learn by iterating optimizing the loss function and then predict or even compose styled literature.
In this blog, we explore using simple RNN (recurrent network neuron) to analyze semantic sentiment. As a shorthand, training vanilla neural nets is optimzation over functions, training RNN recurrent nets is optimization over programs.
First to digitize a piece of text, it’s more than just single out a bag of distinct words, sequence of words matters and also be integrated into info, more over, there is a third method that is far superior, word embeddings. This method keeps the order of words intact as well as encodes similar words with very similar labels.
The math at core can be illustrated with the following diagram:

According to Tim’s explanation, a recurrent layer processes words or input one at a time in a combination with the output from the previous iteration. So, as we progress further in the input sequence, we build a more complex understanding of the text as a whole.
Go over the concept of LSTM again: Long short-term memory has feedback connections. Such a recurrent neural network can process not only single data points, but also entire sequences of data.
Parameters of model 1 is loss=”binary_crossentropy”,optimizer=”rmsprop”,metrics=[‘acc’], model 2 is optimizer = “adam”, loss = “binary_crossentropy”, metrics = [“accuracy”].
To train, model 1 is model.fit(train_data, train_labels, epochs=10, validation_split=0.2), model 2 is
model.fit(train_data, train_data, epochs= 2, batch_size = 500).
It was asked “Is Adam or RMSProp better?”, Adam. Last but not least, Adam (short for Adaptive Moment Estimation) takes the best of both worlds of Momentum and RMSProp. Adam empirically works well, and thus in recent years, it is commonly the go-to choice of deep learning problems.
Once model is fit/trained, evaluate the results by model.evaluate(test_data, test_labels).
Note the batch size is a number of samples processed before the model is updated. The number of epochs is the number of complete passes through the training dataset. The size of a batch must be more than or equal to one and less than or equal to the number of samples in the training dataset.
#sentimental analysis using RNN
%tensorflow_version 2.x # this line is not required unless you are in a notebook
from keras.datasets import imdb
from keras.preprocessing import sequence
import keras
import tensorflow as tf
import os
import numpy as np
VOCAB_SIZE = 88584
MAXLEN = 250
BATCH_SIZE = 64
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = VOCAB_SIZE)
#there is some preprocessing/padding needed for a structured narray
train_data = sequence.pad_sequences(train_data, MAXLEN)
test_data = sequence.pad_sequences(test_data, MAXLEN)
#creating the model
model = tf.keras.Sequential([
tf.keras.layers.Embedding(VOCAB_SIZE, 32),
tf.keras.layers.LSTM(32),
tf.keras.layers.Dense(1, activation="sigmoid")
])
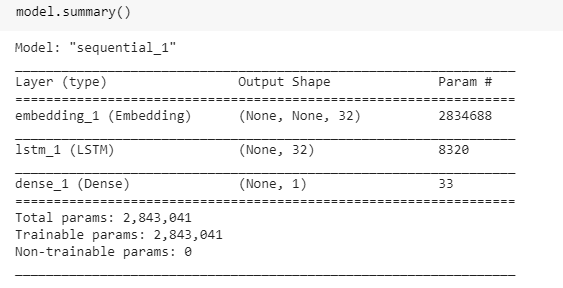
#training
model.compile(loss="binary_crossentropy",optimizer="rmsprop",metrics=['acc'])
history = model.fit(train_data, train_labels, epochs=10, validation_split=0.2)
#results evaluation
results = model.evaluate(test_data, test_labels)
print(results)
#making predictions
word_index = imdb.get_word_index()
def encode_text(text):
tokens = keras.preprocessing.text.text_to_word_sequence(text)
tokens = [word_index[word] if word in word_index else 0 for word in tokens]
return sequence.pad_sequences([tokens], MAXLEN)[0]
text = "that movie was just amazing, so amazing"
encoded = encode_text(text)
print(encoded)
# while were at it lets make a decode function
reverse_word_index = {value: key for (key, value) in word_index.items()}
def decode_integers(integers):
PAD = 0
text = ""
for num in integers:
if num != PAD:
text += reverse_word_index[num] + " "
return text[:-1]
print(decode_integers(encoded))
# now time to make a prediction
def predict(text):
encoded_text = encode_text(text)
pred = np.zeros((1,250))
pred[0] = encoded_text
result = model.predict(pred)
print(result[0])
positive_review = "That movie was! really loved it and would great watch it again because it was amazingly great"
predict(positive_review)
negative_review = "that movie really sucked. I hated it and wouldn't watch it again. Was one of the worst things I've ever watched"
predict(negative_review)
test_review = "that movie was done a while ago it is amazingly positive, excellent great remarkable"
predict(test_review)

I found the result not satisfactory thought. Next, let’s try a long text from local drive.
#read in from local drive
from google.colab import files
path_to_file = list(files.upload().keys())[0]
# Read, then decode for py2 compat.
text = open(path_to_file, 'rb').read().decode(encoding='utf-8')
# length of text is the number of characters in it
print ('Length of text: {} characters'.format(len(text)))
#encode
word_index = imdb.get_word_index()
def encode_text(text):
tokens = keras.preprocessing.text.text_to_word_sequence(text)
tokens = [word_index[word] if word in word_index else 0 for word in tokens]
return sequence.pad_sequences([tokens], MAXLEN)[0]
#predict
def predict(text):
encoded_text = encode_text(text)
pred = np.zeros((1,250))
pred[0] = encoded_text
result = model.predict(pred)
print(result[0])
predict(text)

