Abstract:
This paper presents a method and algorithm to leverage latent semantic analysis through a wide array of document database including regulatory filings in the U.S. and other countries such as Korea, Japan and China, FactSet Transcript database to form thematic portfolio automatically. It works particularly well for abstract themes such as “hydrogen”, “clean energy”, “ocean sustainability”, “water” etc. that are hard to be categorized by conventional industry classification system such as “GICS” or “RBICS”.
Introduction:
Constructing thematic portfolios/indices has been dominated by big indexer such as S&P, MSCI due to the GICS (Global Industry Classification Standard) they co-developed. However as technology advances new business emerge, there are such themes as virtual life, 5G, electric car, hydrogen, clean energy etc. that more and more gain interest in market yet hardly can be tackled by conventional classification system like GICS.
Aiming to solve this problem, we have created a robo-indexing2.0 mechanism that leverage a deeper level of granularity provided by RBICS and additional dimension of company’s relationship. Details can be referenced at this insight article. Based on this technique we’ve launched a flurry of indices such as Yuanta Global NexGen Communication Innovative Technology ETF Units, iShares US Tech Breakthrough Multi-Sectors ETF, SPDR FactSet Innovative Technology ETF, iShares Genomics Immunology and Healthcare ETF, iShares Electric Vehicles and Driving Technology UCITS ETF for large asset managers across the globe.
However, there are limitations for example, the company needs to be mapped by data collection team hence there is a problem of mapping error and time lagging. moreover, abstract concept like 5G, virtual life just don’t have a place anywhere in the industry taxonomy while relationship data spits false positive/negative noise. Over the course of time, company’s profiling may change and selection of sectors need to be monitored periodically to keep valid.
A new algorithm or technique based on latent semantic analysis a.k.a. robo-indexing3.0 is further developed to form highly relevant thematic portfolios/indices automatically and instantaneously. This paper is organized as follow: Section 2 “Related Work” presents a brief overview of the research related to this project. Section 3 “Experimental Method” details our proposed
method and iterations conducted for parameter setting. Section 4 “Results and Evaluation” and Section 5 “Conclusion” details the discussion, further research thoughts and conclusions.
Related Work:
The ultimate goal of constructing thematic portfolio set us to look for similarities between companies or companies’ documents. Mathematically, the similarity is measured by vector distance in the unit of norm. L1 Norm is also called Manhattan or taxicab distance, which take the practical distance, for example (3,4)’s norm = 3+4 =7. L2-Norm also called the Euclid distance in two dimensional space is more commonly used. It’s proportional to cosine similarity which is defined as

Hence if we convert word/phrase/document into vector form, we can easily compute word similarity/distance using above cosine similarity equation. The key in this approach is the very first step of vectorize the text by digitizing each word in it. Because frequently-used stop words such as “all, is, are…” do not actually convey features, TF-IDF(term frequency- Inverse Document Frequency) needs to be applied. TF-IDF’s concept is illustrated in the below equation and example of a simple sentence “I like NLP”
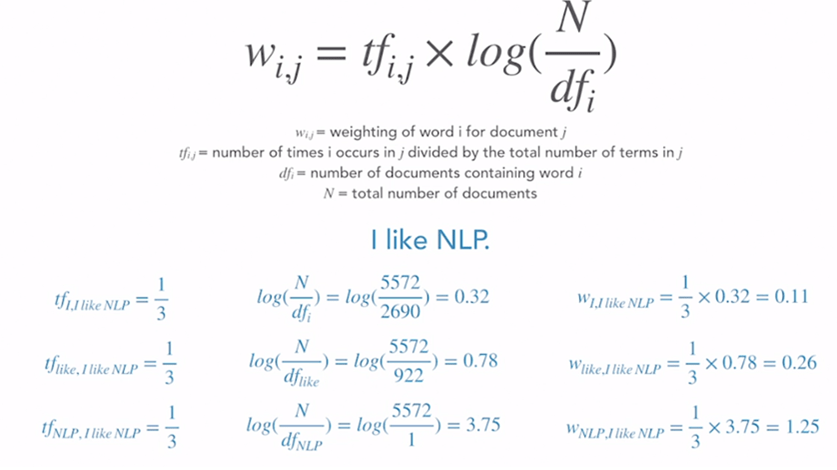
TF-IDF based cosine similarity has been used by some indexer to form theme portfolio (such as Amundi’s Hydrogen mutual fund, however, this method is too course. In addition, one needs to compute over and over again to a “target ideal text” without taking into account the latent embedded information implied by all hydrogen related companies.
Latent Semantic Analysis (LSA) depending on Single Value Decomposition (SVD) mathematical computation, is capable of inferring much deeper relationship that is latent in contexts. It can simulate human meaning-based judgement and perform even better in linguistic interpretation than humans on a large scale. The texts certainly also needs to be processed or cleansed by removing repetitive non-essential words with TF-IDF method. What differentiate LSA from simple cosine similarity is that it takes into all underlying texts, vectorizes them, form a huge sparse matrix, then compute all cosine similarity at once
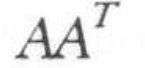
Based on this covariance matrix, one can extract the principle eigen vector eigen value representing multiple semantic meanings of the texts. It’s actually not much different approach than Principle Component Analysis (PCA).

Therefore, to make LSA works well, the collection of texts should not be entirely irrelevant, which will make it hard to surface out the principle component/eigen vector. Furthermore, since it makes no use of word order we shall be wary that it might result in incompleteness or error on some occasions.
Lastly, people may confuse it with the hottest NLP (Natural Language Processing) or AI (Artificial Intelligence) techniques due to the fact that it uses no dictionaries, grammar rules, morphologies or the like yet produce seemingly magic kind of output. LSA does not apply machine-learning (ML) at all however, there are ample progress made using ML processing/interpret semantic data, which is called word2vec and doc2vec. We may explore this venue in the future.
