Word2vec is technique for natural language processing to learn word association from a large corpus of text. Previousely, in techniques such as LSA, words represented locallly without consideration of distributional similarity or inherent notion.
In 2013, Mikolov published his paper on word2vec and this theory is the most advanced up till now.
What’s the main idea of word2vec? It is composed of two algorithms: Skip-grams and CBOW (continuous bag of words).
- Skip-Grams
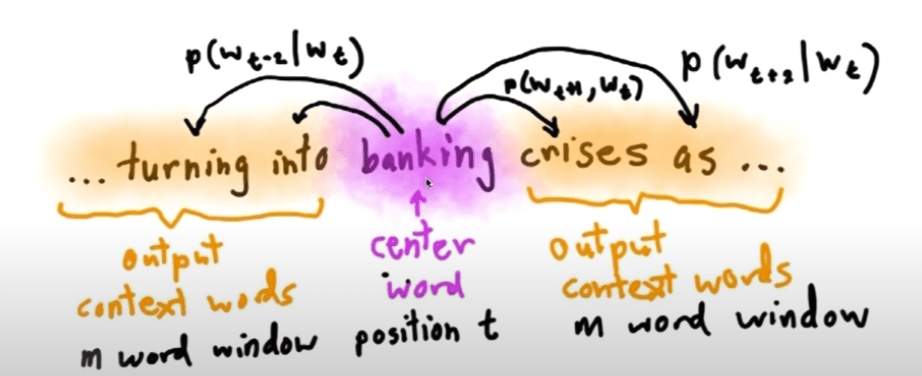

here is an updated prettier version of this concept by Dr.Manning
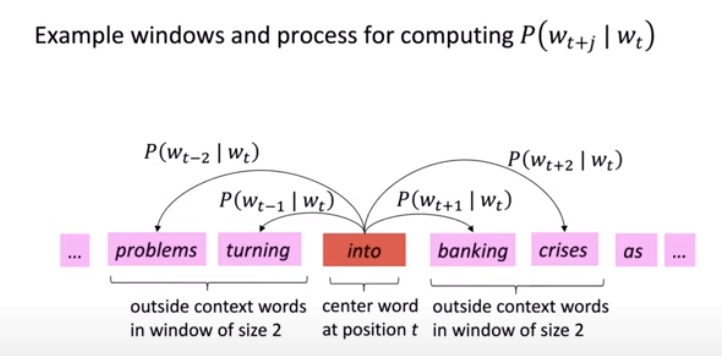
To grasp word2vec, let’s start from the very basic, the vector space model



This measure obviously is not adequate, we know D(1, 3) and D(10, 30) similarity is one, so the number of the word showing up is not taken into account in this cosine similarity computation based on simple bag of words vector space, furthermore, we also don’t consider the distribution of words – you could have same words shown up but one clustered, the other scattered around. Third, if we count every distinctive word as orthogonal vector, it defies the reality that some words such as building and edifice are synonyms so their vectors should be closer to each other.
NLP’s Passing Methods
There are two main approaches bottom-up and top-down. And it relies on dynamic programming which caches intermediate results (memoization). A famous method is Cocke-Kasami-Younger (CKY) parser.
Probabilistic NLP: Bayes Theorem, on which we explore language models: N-gram model

Information Retrieval Toolkits: Smart, MG, Lemur, Terrir, Clairlib, Lucene.
Sentiment Analysis: classification problem, MaxEnt, SVM and Naïve Bayes
