To apply RNN on NLP, the very first thing to figure out is how to represent word. One-hot representation is a naive vectorization method for this purpose. However it can’t catch the simple fact that some words like king and queen, apple and orange are closer in pair rather than out of the pairs. So “featurized representation” is introduced.


Embedding Matrix.

Now we try to apply this on NLP:
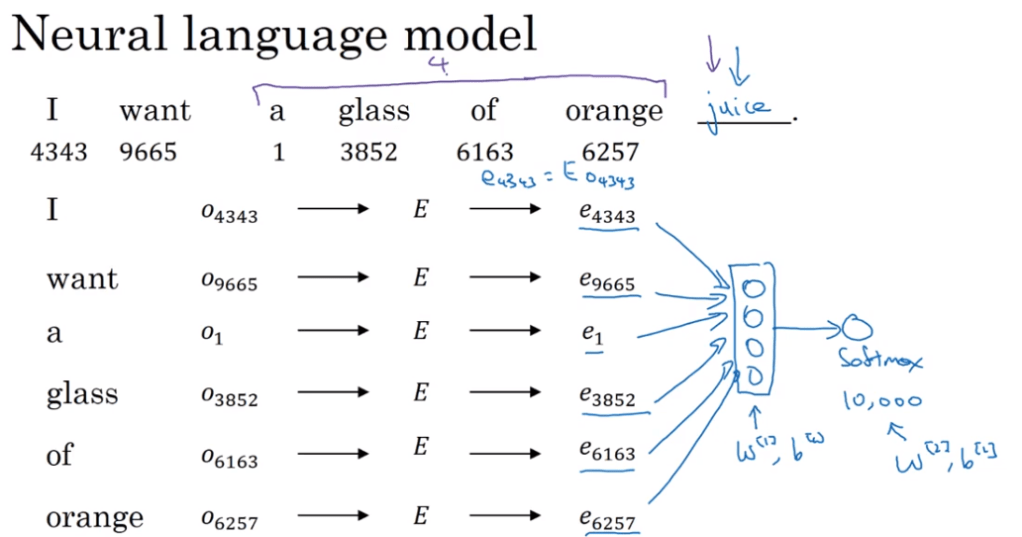
Then tap on the concept of word2vec (mention in previous blog)

Further we’d explore modified learning algorithm using ‘skip-gram’, one of these methods is “negative sampling”.

GloVe (global vectors for word representation),
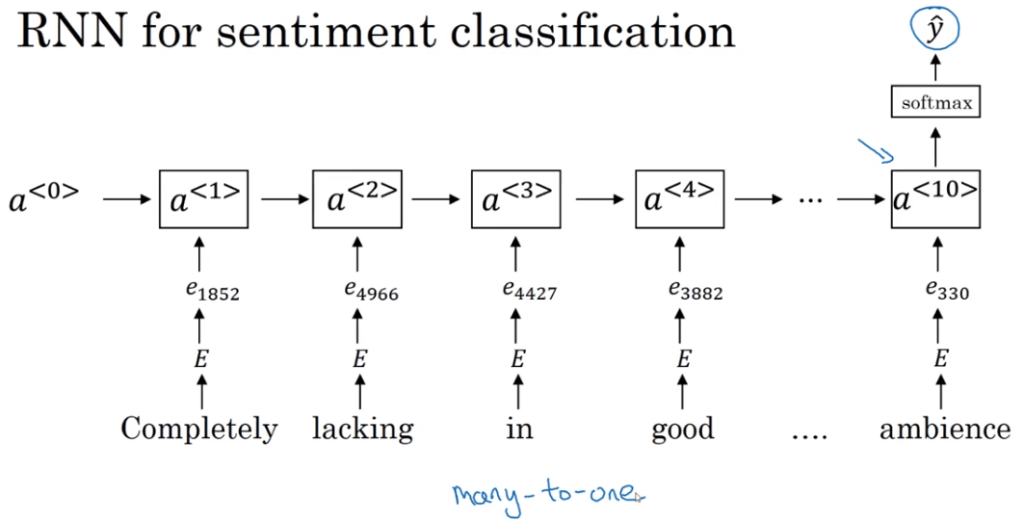
This can be applied in sentiment classification:
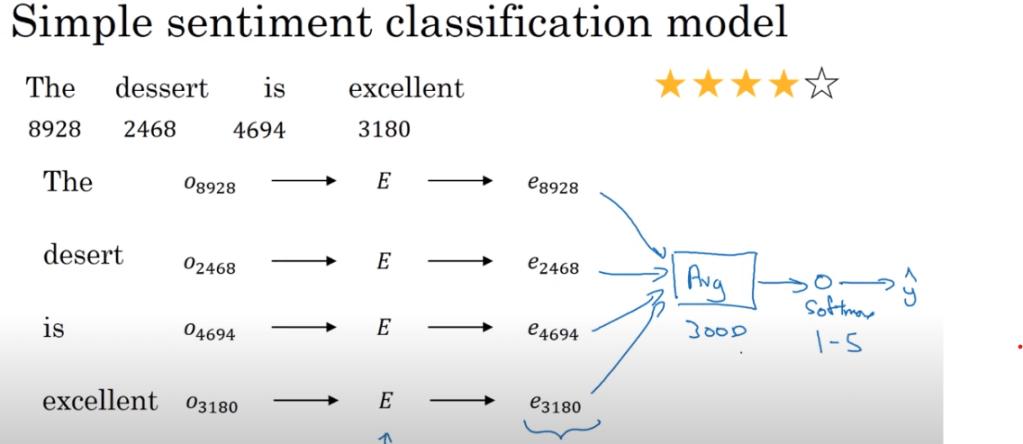
This sentiment calculated by taking the average of softmax is a fair good approximate but it doesn’t consider the effect of preceding or neighbor words such as a negating word, entirely reversing the meaning. For instance applying simply of this approach to imdb movie review dataset one would mistakenly classify a move as positive on seeing multiple “good”, while ignoring the “NOT” in front of these “good”.
RNN comes to play overcoming this drawback: