Now I collected here and there various knowledge and technique in applying NLP, a systematic approach is formed and thanks to Alica Zhao who already summarized the system to be Data Cleaning –> Exploratory Data Analysis(EDA) –> NLP Techniques (lexicon, LSA/LDA and RNN based ML) –> Carry out Tasks(Sentiment/Theme Analysis, Topic Modeling and Text Generation).
The data cleaning and EDA parts are what I need to focus. But first of all, I’d like to reiterate foundational thesis on LSA and LDA difference.
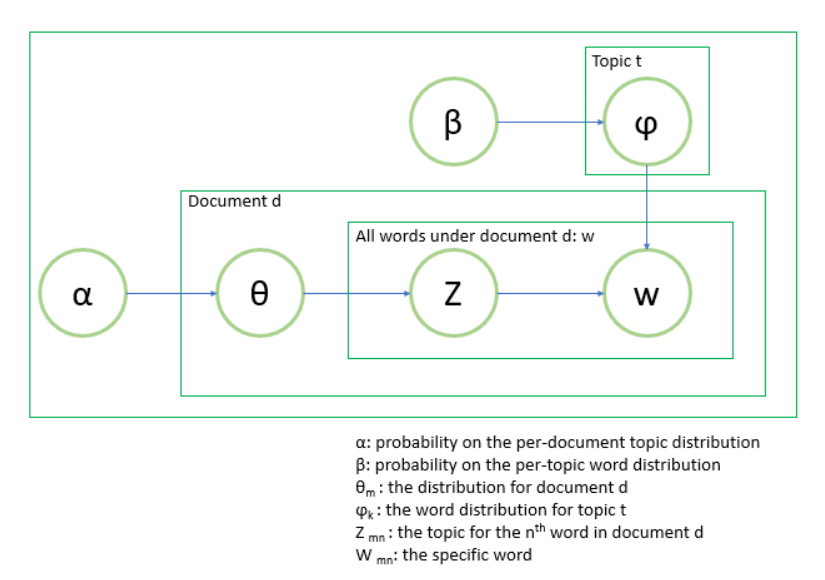
LSA has been elaborated in previous blogs mainly focused on the math of SVD, LDA, according to this blogger(Edward Ma), “LDA is introduced by David Blei, Andrew Ng and Michael O. Jordan in 2003. It is unsupervised learning and topic model is the typical example. The assumption is that each document mix with various topics and every topic mix with various words.”
- LSA is great for capturing semantic relationships and dimensionality reduction.
- LDA is better for interpretable topic modeling and probabilistic analysis.
- LSA is based on matrix factorization (Singular Value Decomposition, or SVD).
- It decomposes the term-document matrix into three matrices: ( U ), ( \Sigma ), and ( V ), where:
- ( U ) represents the relationship between terms and topics.
- ( \Sigma ) represents the strength of topics.
- ( V ) represents the relationship between documents and topics.
- LSA captures the latent semantic structure of the data by reducing the dimensionality of the term-document matrix.
- LDA is a probabilistic generative model.
- It assumes that each document is a mixture of topics, and each topic is a distribution over words.
- LDA uses Dirichlet priors to model the distributions of topics in documents and words in topics.

from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
def build_lda(x_train, num_of_topic=10):
vec = CountVectorizer()
transformed_x_train = vec.fit_transform(x_train)
feature_names = vec.get_feature_names()
lda = LatentDirichletAllocation(
n_components=num_of_topic, max_iter=5,
learning_method='online', random_state=0)
lda.fit(transformed_x_train)
return lda, vec, feature_names
def display_word_distribution(model, feature_names, n_word):
for topic_idx, topic in enumerate(model.components_):
print("Topic %d:" % (topic_idx))
words = []
for i in topic.argsort()[:-n_word - 1:-1]:
words.append(feature_names[i])
print(words)
lda_model, vec, feature_names = build_lda(x_train)
display_word_distribution(
model=lda_model, feature_names=feature_names,
n_word=5)
Data cleaning is essential:
Make text all lower case
Remove punctuation
Remove numerical values
Remove common non-sensical text (/n)
Tokenize text
Remove stop words
More data cleaning steps after tokenization:
Stemming / lemmatization
Parts of speech tagging
Create bi-grams or tri-grams
Deal with typos
And more…
# Let's take a look at our data again
next(iter(data.keys()))
# Notice that our dictionary is currently in key: comedian, value: list of text format
next(iter(data.values()))
# We are going to change this to key: comedian, value: string format
def combine_text(list_of_text):
'''Takes a list of text and combines them into one large chunk of text.'''
combined_text = ' '.join(list_of_text)
return combined_text
# Combine it!
data_combined = {key: [combine_text(value)] for (key, value) in data.items()}
# We can either keep it in dictionary format or put it into a pandas dataframe
import pandas as pd
pd.set_option('max_colwidth',150)
data_df = pd.DataFrame.from_dict(data_combined).transpose()
data_df.columns = ['transcript']
data_df = data_df.sort_index()
data_df
# Let's take a look at the transcript for Ali Wong
data_df.transcript.loc['ali']
# Apply a first round of text cleaning techniques
import re
import string
def clean_text_round1(text):
'''Make text lowercase, remove text in square brackets, remove punctuation and remove words containing numbers.'''
text = text.lower()
text = re.sub('\[.*?\]', '', text)
text = re.sub('[%s]' % re.escape(string.punctuation), '', text)
text = re.sub('\w*\d\w*', '', text)
return text
round1 = lambda x: clean_text_round1(x)
# Let's take a look at the updated text
data_clean = pd.DataFrame(data_df.transcript.apply(round1))
data_clean
# Apply a second round of cleaning
def clean_text_round2(text):
'''Get rid of some additional punctuation and non-sensical text that was missed the first time around.'''
text = re.sub('[‘’“”…]', '', text)
text = re.sub('\n', '', text)
return text
round2 = lambda x: clean_text_round2(x)
# NOTE: This data cleaning aka text pre-processing step could go on for a while, but we are going to stop for now. After going through some analysis techniques, if you see that the results don't make sense or could be improved, you can come back and make more edits such as:
# Mark 'cheering' and 'cheer' as the same word (stemming / lemmatization)
# Combine 'thank you' into one term (bi-grams)
# And a lot more...
# Document-Term Matrix
# For many of the techniques we'll be using in future notebooks, the text must be tokenized, meaning broken down into smaller pieces. The most common tokenization technique is to break down text into words. We can do this using scikit-learn's CountVectorizer, where every row will represent a different document and every column will represent a different word.
# Note scikit-learn also offer sklearn.feature_extraction.text import TfidfVectorizer
# We are going to create a document-term matrix using CountVectorizer, and exclude common English stop words
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(stop_words='english')
data_cv = cv.fit_transform(data_clean.transcript)
data_dtm = pd.DataFrame(data_cv.toarray(), columns=cv.get_feature_names())
data_dtm.index = data_clean.index
data_dtm
# Let's also pickle the cleaned data (before we put it in document-term matrix format) and the CountVectorizer object
data_clean.to_pickle('data_clean.pkl')
pickle.dump(cv, open("cv.pkl", "wb"))
Next, showcase her codes on LDA application using gensim.
# Document-Term Matrix
# For many of the techniques we'll be using in future notebooks, the text must be tokenized, meaning broken down into smaller pieces. The most common tokenization technique is to break down text into words. We can do this using scikit-learn's CountVectorizer, where every row will represent a different document and every column will represent a different word.
# Note scikit-learn also offer sklearn.feature_extraction.text import TfidfVectorizer
# We are going to create a document-term matrix using CountVectorizer, and exclude common English stop words
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(stop_words='english')
data_cv = cv.fit_transform(data_clean.transcript)
data_dtm = pd.DataFrame(data_cv.toarray(), columns=cv.get_feature_names())
data_dtm.index = data_clean.index
data_dtm
# Let's also pickle the cleaned data (before we put it in document-term matrix format) and the CountVectorizer object
data_clean.to_pickle('data_clean.pkl')
pickle.dump(cv, open("cv.pkl", "wb"))
# Import the necessary modules for LDA with gensim
# Terminal / Anaconda Navigator: conda install -c conda-forge gensim
from gensim import matutils, models
import scipy.sparse
# import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# One of the required inputs is a term-document matrix
tdm = data.transpose()
tdm.head()
# We're going to put the term-document matrix into a new gensim format, from df --> sparse matrix --> gensim corpus
sparse_counts = scipy.sparse.csr_matrix(tdm)
corpus = matutils.Sparse2Corpus(sparse_counts)
# Gensim also requires dictionary of the all terms and their respective location in the term-document matrix
cv = pickle.load(open("cv_stop.pkl", "rb"))
id2word = dict((v, k) for k, v in cv.vocabulary_.items())
# Now that we have the corpus (term-document matrix) and id2word (dictionary of location: term), we need to specify two other parameters - the number of topics and the number of passes. Let's start the number of topics at 2, see if the results make sense, and increase the number from there.
# Now that we have the corpus (term-document matrix) and id2word (dictionary of location: term),
# we need to specify two other parameters as well - the number of topics and the number of passes
lda = models.LdaModel(corpus=corpus, id2word=id2word, num_topics=2, passes=10)
lda.print_topics()
# LDA for num_topics = 3
lda = models.LdaModel(corpus=corpus, id2word=id2word, num_topics=3, passes=10)
lda.print_topics()
# LDA for num_topics = 4
lda = models.LdaModel(corpus=corpus, id2word=id2word, num_topics=4, passes=10)
lda.print_topics()
#Next to make the topics more sensible, some pruning work id needed
# Attempt #2 (Nouns Only)
# One popular trick is to look only at terms that are from one part of speech (only nouns, only adjectives, etc.). Check out the UPenn tag set: https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html.
# Let's create a function to pull out nouns from a string of text
from nltk import word_tokenize, pos_tag
def nouns(text):
'''Given a string of text, tokenize the text and pull out only the nouns.'''
is_noun = lambda pos: pos[:2] == 'NN'
tokenized = word_tokenize(text)
all_nouns = [word for (word, pos) in pos_tag(tokenized) if is_noun(pos)]
return ' '.join(all_nouns)
# Read in the cleaned data, before the CountVectorizer step
data_clean = pd.read_pickle('data_clean.pkl')
data_clean
# Apply the nouns function to the transcripts to filter only on nouns
data_nouns = pd.DataFrame(data_clean.transcript.apply(nouns))
data_nouns
# Create a new document-term matrix using only nouns
from sklearn.feature_extraction import text
from sklearn.feature_extraction.text import CountVectorizer
# Re-add the additional stop words since we are recreating the document-term matrix
add_stop_words = ['like', 'im', 'know', 'just', 'dont', 'thats', 'right', 'people', 'youre', 'got', 'gonna', 'time', 'think', 'yeah', 'said']
stop_words = text.ENGLISH_STOP_WORDS.union(add_stop_words)
# Recreate a document-term matrix with only nouns
cvn = CountVectorizer(stop_words=stop_words)
data_cvn = cvn.fit_transform(data_nouns.transcript)
data_dtmn = pd.DataFrame(data_cvn.toarray(), columns=cvn.get_feature_names())
data_dtmn.index = data_nouns.index
data_dtmn
# Create the gensim corpus
corpusn = matutils.Sparse2Corpus(scipy.sparse.csr_matrix(data_dtmn.transpose()))
# Create the vocabulary dictionary
id2wordn = dict((v, k) for k, v in cvn.vocabulary_.items())
# Let's start with 2 topics
ldan = models.LdaModel(corpus=corpusn, num_topics=2, id2word=id2wordn, passes=10)
ldan.print_topics()
# Let's try topics = 3
ldan = models.LdaModel(corpus=corpusn, num_topics=3, id2word=id2wordn, passes=10)
ldan.print_topics()
# Let's try 4 topics
ldan = models.LdaModel(corpus=corpusn, num_topics=4, id2word=id2wordn, passes=10)
ldan.print_topics()
#further pruning
# Let's create a function to pull out nouns from a string of text
def nouns_adj(text):
'''Given a string of text, tokenize the text and pull out only the nouns and adjectives.'''
is_noun_adj = lambda pos: pos[:2] == 'NN' or pos[:2] == 'JJ'
tokenized = word_tokenize(text)
nouns_adj = [word for (word, pos) in pos_tag(tokenized) if is_noun_adj(pos)]
return ' '.join(nouns_adj)
# Apply the nouns function to the transcripts to filter only on nouns
data_nouns_adj = pd.DataFrame(data_clean.transcript.apply(nouns_adj))
data_nouns_adj
# Create a new document-term matrix using only nouns and adjectives, also remove common words with max_df
cvna = CountVectorizer(stop_words=stop_words, max_df=.8)
data_cvna = cvna.fit_transform(data_nouns_adj.transcript)
data_dtmna = pd.DataFrame(data_cvna.toarray(), columns=cvna.get_feature_names())
data_dtmna.index = data_nouns_adj.index
data_dtmna
# Create the gensim corpus
corpusna = matutils.Sparse2Corpus(scipy.sparse.csr_matrix(data_dtmna.transpose()))
# Create the vocabulary dictionary
id2wordna = dict((v, k) for k, v in cvna.vocabulary_.items())
# Let's start with 2 topics
ldana = models.LdaModel(corpus=corpusna, num_topics=2, id2word=id2wordna, passes=10)
ldana.print_topics()
# Let's try 3 topics
ldana = models.LdaModel(corpus=corpusna, num_topics=3, id2word=id2wordna, passes=10)
ldana.print_topics()
# Let's try 4 topics
ldana = models.LdaModel(corpus=corpusna, num_topics=4, id2word=id2wordna, passes=10)
ldana.print_topics()
# Our final LDA model (for now)
ldana = models.LdaModel(corpus=corpusna, num_topics=4, id2word=id2wordna, passes=80)
ldana.print_topics()
# [(0,
# '0.009*"joke" + 0.005*"mom" + 0.005*"parents" + 0.004*"hasan" + 0.004*"jokes" + 0.004*"anthony" + 0.003*"nuts" + 0.003*"dead" + 0.003*"tit" + 0.003*"twitter"'),
# (1,
# '0.005*"mom" + 0.005*"jenny" + 0.005*"clinton" + 0.004*"friend" + 0.004*"parents" + 0.003*"husband" + 0.003*"cow" + 0.003*"ok" + 0.003*"wife" + 0.003*"john"'),
# (2,
# '0.005*"bo" + 0.005*"gun" + 0.005*"guns" + 0.005*"repeat" + 0.004*"um" + 0.004*"ass" + 0.004*"eye" + 0.004*"contact" + 0.003*"son" + 0.003*"class"'),
# (3,
# '0.006*"ahah" + 0.004*"nigga" + 0.004*"gay" + 0.003*"dick" + 0.003*"door" + 0.003*"young" + 0.003*"motherfucker" + 0.003*"stupid" + 0.003*"bitch" + 0.003*"mad"')]
# These four topics look pretty decent. Let's settle on these for now.
# Topic 0: mom, parents
# Topic 1: husband, wife
# Topic 2: guns
# Topic 3: profanity
# Let's take a look at which topics each transcript contains
corpus_transformed = ldana[corpusna]
list(zip([a for [(a,b)] in corpus_transformed], data_dtmna.index))
