The format of original labeled file is as simple as the following

The codes are derived from set of codes from https://github.com/DiveshRKubal/Data-Science-Use-Cases/blob/master/News%20Classification/News%20Classification.ipynb
import pandas as pd
import matplotlib.pyplot as plt
import pickle
import seaborn as sns
import nltk
from nltk.corpus import stopwords
from wordcloud import WordCloud ,STOPWORDS
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from nltk.tokenize import word_tokenize
import re
import warnings
warnings.filterwarnings("ignore")
data_dir = 'C:\\Users\\ncarucci\\AMD'
data = pd.read_csv(os.path.join(data_dir, 'hydrogen_doc2vec_token.csv'))
data.head()
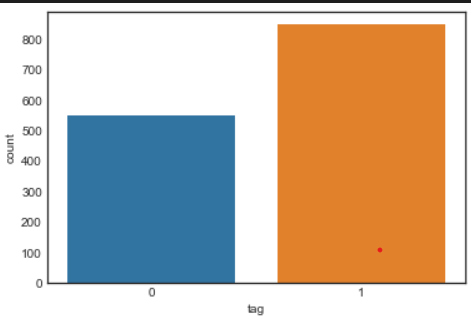
data['tag'].unique()
sns.countplot(data.tag)
data[‘News_length’] = data[‘clean_documents’].str.len()
print(data[‘News_length’])
sns.distplot(data[‘News_length’]).set_title(‘News length distribution’)

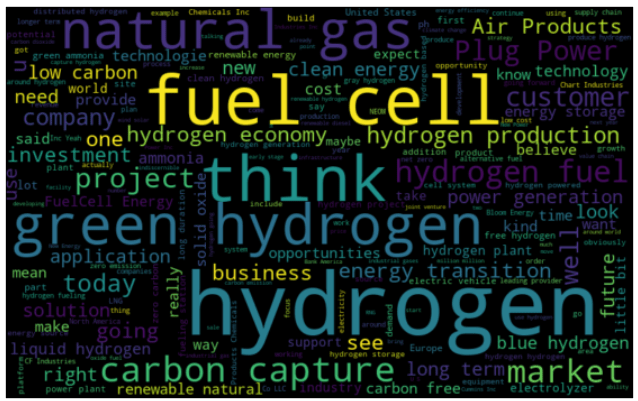
Then create wordcloud to have a better view of the data topics
def create_wordcloud(words):
wordcloud = WordCloud(width=800, height=500, random_state=21, max_font_size=110).generate(words)
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.show()
subset=data[data.tag == 1]
text=subset.clean_documents.values
words =" ".join(text)
create_wordcloud(words)
Next, text processing/sanitization is a critical step.
def process_text(text):
text = text.lower().replace('\n',' ').replace('\r','').strip()
text = re.sub(' +', ' ', text)
text = re.sub(r'[^\w\s]','',text)
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(text)
filtered_sentence = [w for w in word_tokens if not w in stop_words]
filtered_sentence = []
for w in word_tokens:
if w not in stop_words:
filtered_sentence.append(w)
text = " ".join(filtered_sentence)
return text
data['Text_parsed'] = data['clean_documents'].apply(process_text)
data.head()
Note some additional cleaning steps are included here for reference
def clean_text_round1(text):
'''Make text lowercase, remove text in square brackets, remove punctuation and remove words containing numbers.'''
text = text.lower()
text = re.sub('\[.*?\]', '', text) #square brackets
text = re.sub('[%s]' % re.escape(string.punctuation), '', text) #string punctuations
text = re.sub('\w*\d\w*', '', text) #only alphabet words
return text
round1 = lambda x: clean_text_round1(x)
# Let's take a look at the updated text
data_clean = pd.DataFrame(data_df.transcript.apply(round1))
data_clean
# Apply a second round of cleaning
def clean_text_round2(text):
'''Get rid of some additional punctuation and non-sensical text that was missed the first time around.'''
text = re.sub('[‘’“”…]', '', text)
text = re.sub('\n', '', text)
return text
round2 = lambda x: clean_text_round2(x)
#screen only the nouns
def nouns(text):
'''Given a string of text, tokenize the text and pull out only the nouns.'''
is_noun = lambda pos: pos[:2] == 'NN'
tokenized = word_tokenize(text)
all_nouns = [word for (word, pos) in pos_tag(tokenized) if is_noun(pos)]
return ' '.join(all_nouns)
# Read in the cleaned data, before the CountVectorizer step
data_clean = pd.read_pickle('data_clean.pkl')
data_clean
# Apply the nouns function to the transcripts to filter only on nouns
data_nouns = pd.DataFrame(data_clean.transcript.apply(nouns))
Data preparation also include label encoding and split to training and test datasets:
#Label Encoding
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
data['Category_target']= label_encoder.fit_transform(data['tag'])
#Split data in testing and training
X_train, X_test, y_train, y_test = train_test_split(data['Text_parsed'],
data['Category_target'],
test_size=0.2,
random_state=8)
ngram_range = (1,2)
min_df = 10
max_df = 1.
max_features = 100
tfidf = TfidfVectorizer(encoding='utf-8',
ngram_range=ngram_range,
stop_words=None,
lowercase=False,
max_df=max_df,
min_df=min_df,
max_features=max_features,
norm='l2',
sublinear_tf=True)
features_train = tfidf.fit_transform(X_train).toarray()
labels_train = y_train
print(features_train)
features_test = tfidf.transform(X_test).toarray()
labels_test = y_test
print(features_test.shape)
Now to build vectors for models
#Building Models
#Doc2Vec
bbc = pd.DataFrame()
bbc['Text'] = data['Text_parsed']
bbc['Category'] = data['Category_target']
bbc.head()
from tqdm import tqdm
tqdm.pandas(desc="progress-bar")
from gensim.models import Doc2Vec
from sklearn import utils
import gensim
from gensim.models.doc2vec import TaggedDocument
import re
def label_sentences(corpus, label_type):
"""
Gensim's Doc2Vec implementation requires each document/paragraph to have a label associated with it.
We do this by using the TaggedDocument method. The format will be "TRAIN_i" or "TEST_i" where "i" is
a dummy index of the post.
"""
labeled = []
for i, v in enumerate(corpus):
label = label_type + '_' + str(i)
labeled.append(TaggedDocument(v.split(), [label]))
return labeled
X_train, X_test, y_train, y_test = train_test_split(bbc.Text, bbc.Category, random_state=0, test_size=0.3)
X_train = label_sentences(X_train, 'Train')
X_test = label_sentences(X_test, 'Test')
all_data = X_train + X_test
model_dbow = Doc2Vec(dm=0, vector_size=300, negative=5, min_count=1, alpha=0.065, min_alpha=0.065)
model_dbow.build_vocab([x for x in tqdm(all_data)])
for epoch in range(30):
model_dbow.train(utils.shuffle([x for x in tqdm(all_data)]), total_examples=len(all_data), epochs=1)
model_dbow.alpha -= 0.002
model_dbow.min_alpha = model_dbow.alpha
import numpy as np
def get_vectors(model, corpus_size, vectors_size, vectors_type):
"""
Get vectors from trained doc2vec model
:param doc2vec_model: Trained Doc2Vec model
:param corpus_size: Size of the data
:param vectors_size: Size of the embedding vectors
:param vectors_type: Training or Testing vectors
:return: list of vectors
"""
vectors = np.zeros((corpus_size, vectors_size))
for i in range(0, corpus_size):
prefix = vectors_type + '_' + str(i)
vectors[i] = model.docvecs[prefix]
return vectors
train_vectors_dbow = get_vectors(model_dbow, len(X_train), 300, 'Train')
test_vectors_dbow = get_vectors(model_dbow, len(X_test), 300, 'Test')
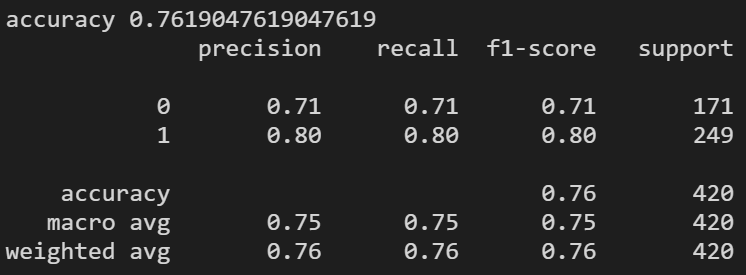
Run logistic regression model
#Logistic Regression
model = LogisticRegression(n_jobs=1, C=1e5)
model = model.fit(train_vectors_dbow, y_train)
model_prediction = model.predict(test_vectors_dbow)
print('accuracy %s' % accuracy_score(model_prediction, y_test))
print(classification_report(y_test, model_prediction))
#GaussianNB
model = GaussianNB()
model = model.fit(train_vectors_dbow, y_train)
model_prediction = model.predict(test_vectors_dbow)
print('accuracy %s' % accuracy_score(model_prediction, y_test))
print(classification_report(y_test, model_prediction))

#Random Forest doesn't work not defined
model = RandomForestClassifier()
model = model.fit(train_vectors_dbow, y_train)
model_prediction = model.predict(test_vectors_dbow)
print('accuracy %s' % accuracy_score(model_prediction, y_test))
print(classification_report(y_test, model_prediction))
#RNN can't run here have to use colab tensorflow, reference IMDB_Sentiment.ipynb script
#prepare the encoded text is key
word_index = imdb.get_word_index()
def encode_text(text):
tokens = keras.preprocessing.text.text_to_word_sequence(text)
tokens = [word_index[word] if word in word_index else 0 for word in tokens]
return sequence.pad_sequences([tokens], MAXLEN)[0]
text = "that movie was just amazing, so amazing"
encoded = encode_text(text)
print(encoded)
#creating the model
model = tf.keras.Sequential([
tf.keras.layers.Embedding(VOCAB_SIZE, 32),
tf.keras.layers.LSTM(32),
# tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dense(1, activation="sigmoid")
])
