draft on detailing entire process
be built. Known as “Factory Zero” GM is investing $2.2 billion into the facility and plans to build four different electric vehicles on site. An estimated 2,200 workers will eventually work at the factory, according to the company.\nGM would not say when the electric Silverado would be available for purchase, but the company has previously committed to selling 30 electric vehicles globally by the end of 2025. GM has also said it will move all of its passenger vehicles to electric by 2035, according estimated built zero site build investing silverado committed move worker plan factory 2200 billion end available according 2025 selling globally facility passenger purchase previously work would different vehicle 2035 known four eventually say electric estimated built zero site build investing silverado committed move worker plan factory 2200 billion end available according 2025 selling globally facility passenger purchase previously work would different vehicle 2035 known four eventually say electric
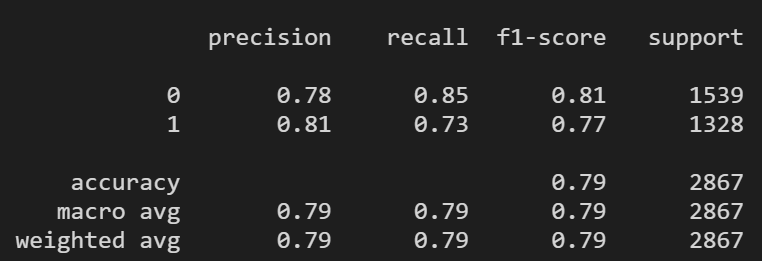
try doc sample of hydrogen_labe (>9000 records) returns the best result. If set dm=1(considering order), it’s worse than dm=0, accuracy is 0.71 and recall rate of sample 1 is 0.73.
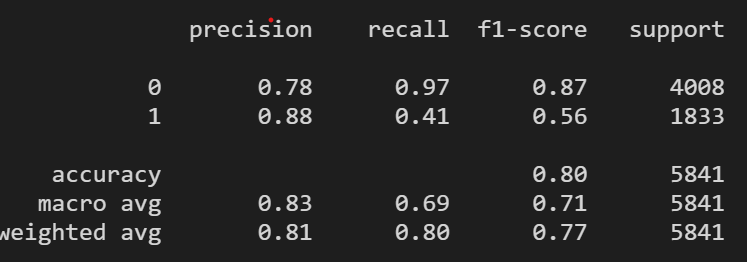
try hydrogen_label_extended(>15000) returns so so, recall rate of those sample 1 is only 41%.
try hydrogen_label_extended on dm=1 considering order returns even worse result with recall rate of 0.15.
about Random Forest
Introduced by Leo Breiman and Adele Cutler in the 2000s [1], RF build prediction ensembles using decision trees that are generated randomly in randomly selected subspace of data [3]. The decision trees generated are used to represent the rules that result from modeling. Training datasets contain several attributes, in the case of RF, randomness is also applied to choose the best attribute to split on at different levels of the decision tree. The average is calculated from random classifiers.
Fig. 1. A general architecture of a random forest [4].
Sentiment Mining of Movie Reviews Using RF with Tuned Hyperparameters 2014
text size: Sentiment analysis on sentence level is becoming very famous research trend with the growth of social media
model of unigram or n-gram: For the purpose of sentiment analysis is unigram model is considered to be best as far as the results are considered [1,2, 6]. All the experiments and evaluation provided in this report make use of Unigram as a feature selection model and which also provides some good results compared to other model like bigram [11].
200,000 transcripts per Ruggero HIT score
Random Forest classifier provides two types of randomness, first is with respect to data and second is with respect to features. Random Forest classifier uses the concept of Bagging and Bootstrapping [14]. Random Forest works as shown below.
NLP in Indexing workflow Contents
- Three generational Evolution of thematic indexing: market benchmark –> structured data based connection –> machine learning based NLP construction
- NLP theory: information retrieval book, articles on semantic analysis LSA LDA, sentiment
- NLP practice: data collection, data cleaning, data exploration, similarity score, theme construction
