In counting the word frequency, there is zero denominator issue and Laplace smoothing is applied to solve it. Laplace Smoothing idea is simple as just to add “one” into the count for every word even those never has shown up. This approach is not a maximum like liihood estimate. It’s a blunt instrument, making big changes in the counts.
So there are better methods to account for simple add-1 smoothing, one is back-off and the other is interpolation.

If there are out-of-vocabulary (OOV) words, we assign a special token “UNK” to them and train.
there are huge web-scale n-grams such as when we introduce Google’s huge N-gram corpus. we can apply pruning by kicking out singletons or setting a threshold of counts shown up. Or apply more sophisticated pruning such as entropy based.
Let’s talk about more advanced methods of smoothing. Unigram prior smoothing is still kind of interpolation. In essence, the crux is to Use the count of things you’ve seen once. The approach is called “Good Turing Smooth“. A notation frequency of frequency c is notated as Nc. Another smoothing method is called “Kneser-Ney Smoothing”.
Spelling Correction
Naive Bayes based text classification model, bag of words is used, which loses the critical info about the order of words. The Bayes model is expressed mathematically as

Generative Model for Multinomial Naive Bayes with an example:

to evaluate text classifier we use precision, recall and F measure.
Sentiment analysis. There are a big issue like all positive words piled up but in the end being negated by one simple word No. Baseline Naive Bayes models are not adequate.
Linguistic inquiry and word lexicon, a lot more categories such as cognitive process, affective process etc. are also extracted and labeled, or Bing Liu’s opinion lexicon. There is a sentiWordNet at home page http://sentiwordnet.isti.cnr.it/ all senses automatically annotated for degrees of positivity, negativity, and neutrality/objectiveness. Polarity of word in each document varies. Negation and scalability needs to be done.
Maxent Models and Discriminative Estimation(conditional model), relative to which is called generative models(joint models), generate observed data from hidden stuff. All the classic statNLP models are joint/generative models: N-gram models, Naive Bayes classifiers, hidden Markov Models, probabilistic context-free grammars, IBM machine translation alignment models. discriminative(conditional) models take the data as given, and put a probability over hidden structure given that data.

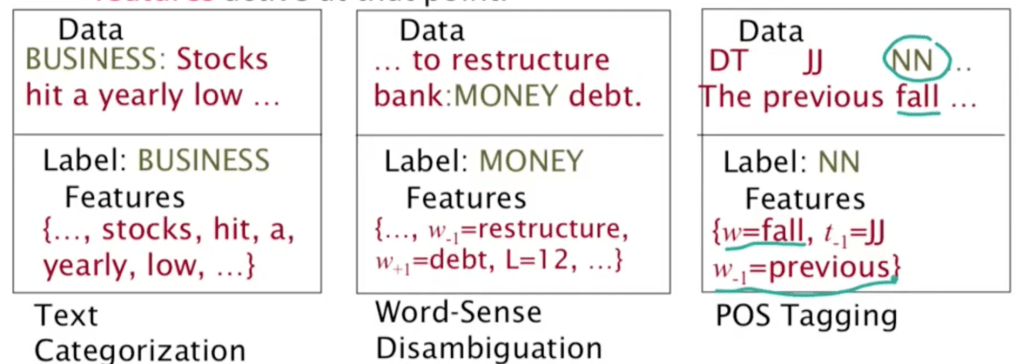
We will use feature to expand/utilize these two models for text analysis. Feature is a function with a bounded real value. For example,