Build a Maxent Model. 6:23
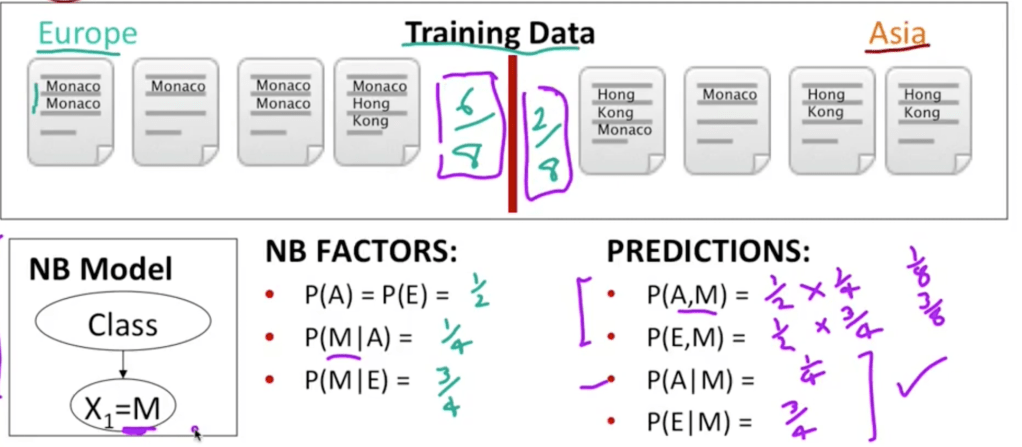
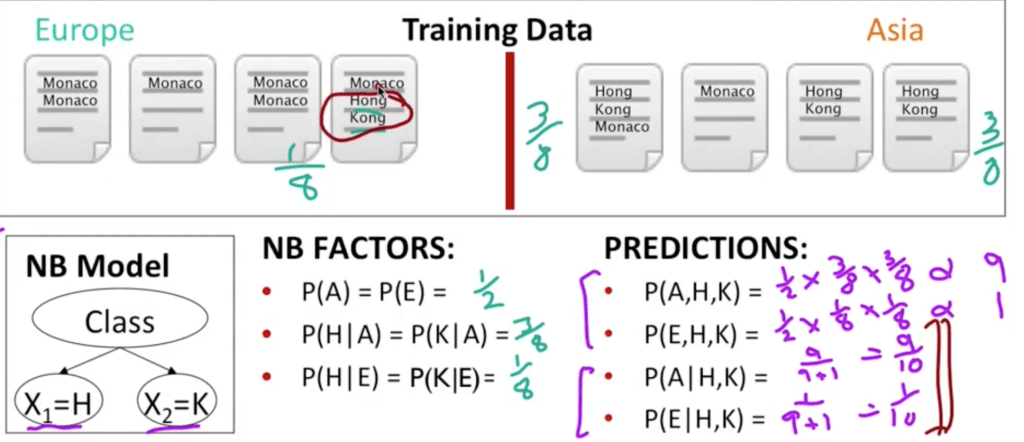
NB models multi-count correlated evidence such as Hong and Kong, Maximum Entropy models (Maxent) pretty much solve this problem.
L-BFGS is chosen for the parameter optimization in this nlp course.
Named Entity Recognition NER. The crucial and difficult part is the evaluation standard is not based on token but per ENTITY. Low level information extraction – searching a string of words is apparently inadequate so we need to apply more intelligent machine learning models to accomplish the goal.
Sequence Model for NER. Certainly for ML, manual labeling is needed. Features for sequence labeling, what we often use first is Words, including the current word and previous/next word providing context, the other is other kinds of inferred linguistic classification part of speech tags, label context. For example, you can use B I labeling system inside or outside. or beginning, latter part or outside, which will substantially increase the size of computation.
Further, developing to Maximum Entropy Markov Models(MEMMs) or Conditional Markov Models.
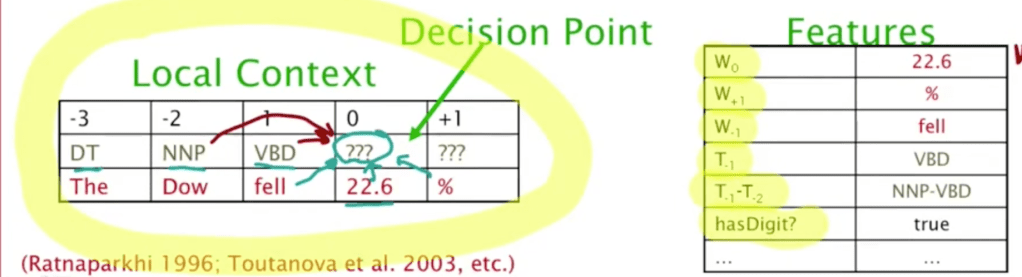
In applying there is Beam Inference and Viterbi Inference(Viterbi invented lots of this kind of algorithms)
Relative to Information Extraction, there is another concept – Relation Extraction. That’s how this model’s name is from. Now let’s see some examples with overlapping features. Maxent model Handles overlapping features well but not on model feature interactions.
Compare Conditional and joint maxent models .
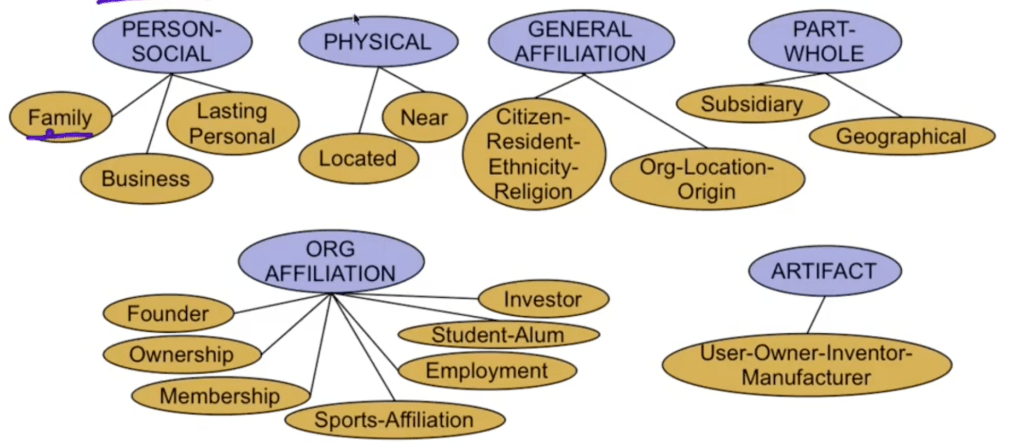
PER-GPE person to location
ORG-ORG XYZ, the parent company of ABC
PER-PER John’s wife Yoko
Perhaps the easiest way to extract relation is to use hand-built pattern. for example

Supervised ML to extract relations. Entity based features, word based and syntax sequence features. there are semi-supervised or unsupervised relation extraction.
Go back to Maxent model again with first understand maximizing entropy mean, so what is entropy specifically here?

