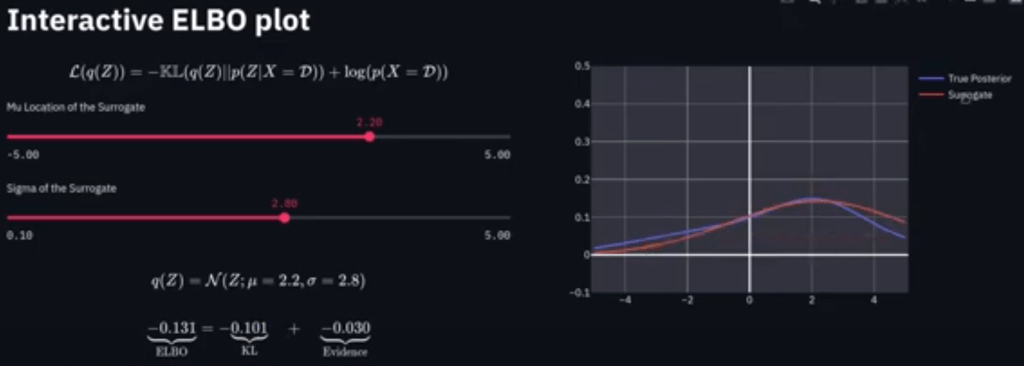
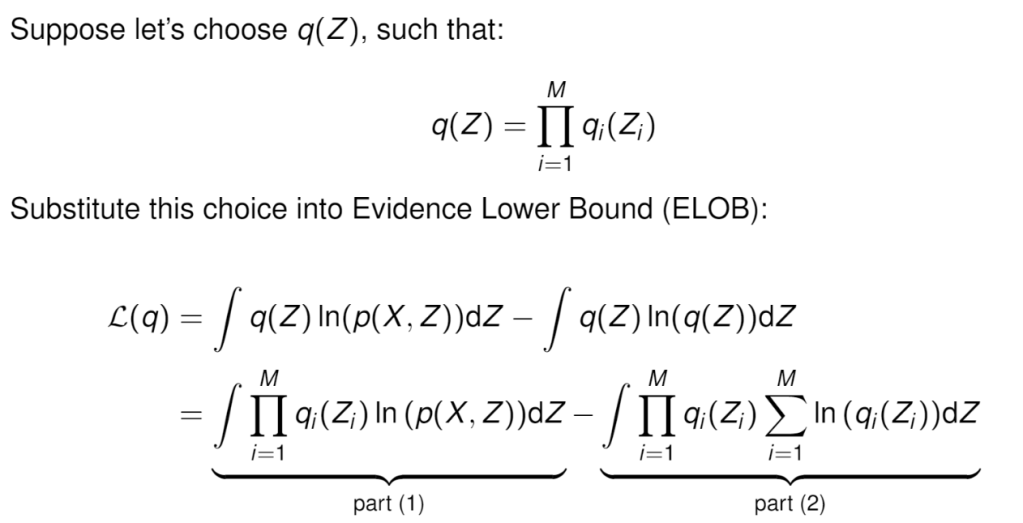This is referenced from Machine Learning and Simulation.
Since calculate the posterior of probability of multi-dimensional latent variable theta given a set of data D is impossible -intractable – mathematicians think of using surrogate(approximate) distribution.

Then the question is to apply KL divergence to minimize the difference between the two as shown above. After some math manipulation, we get
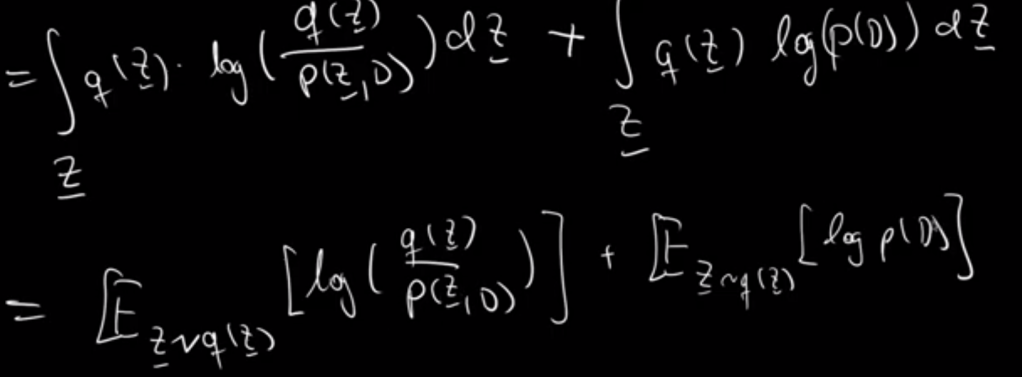

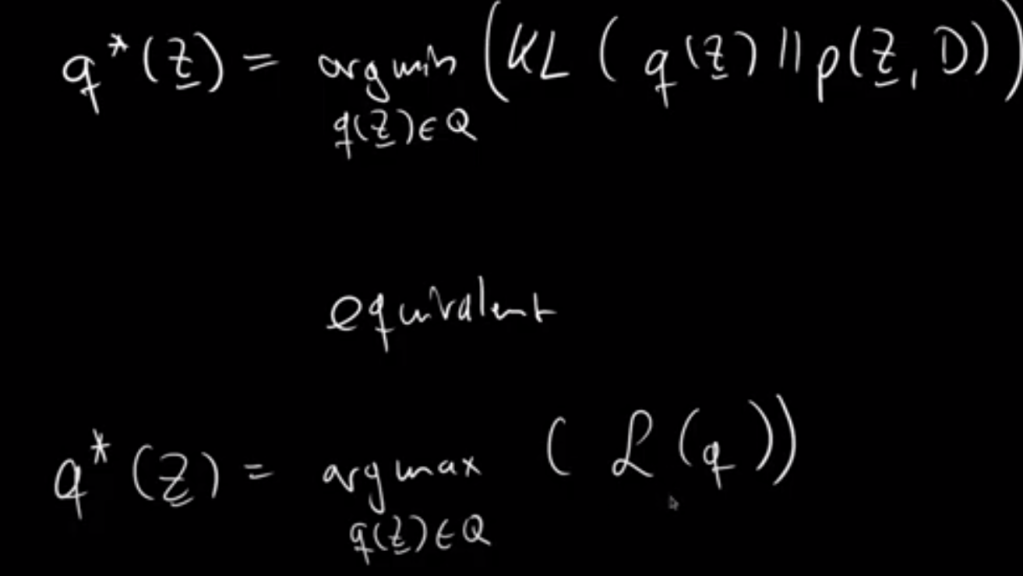
From Dr.Xu’s material, the equations are more clear in how this math trick /q function is introduced
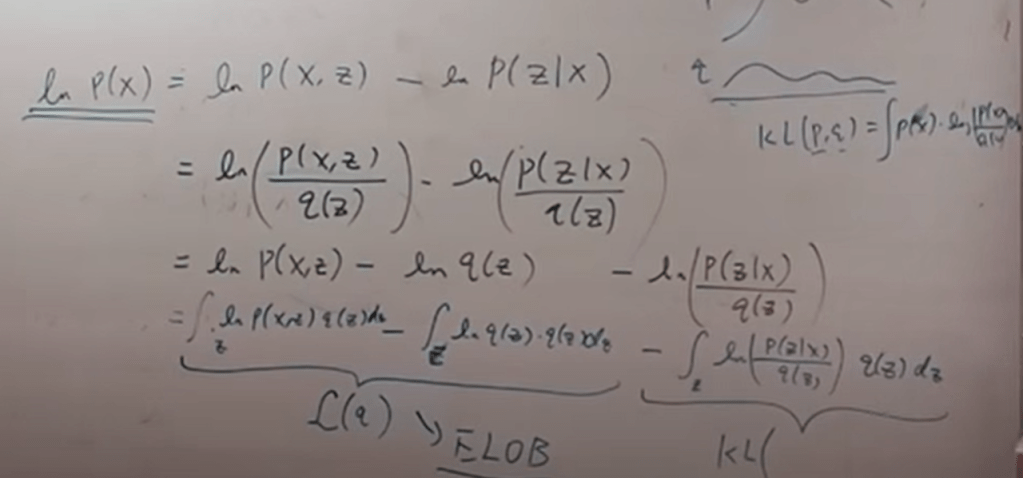
The prior P(x)
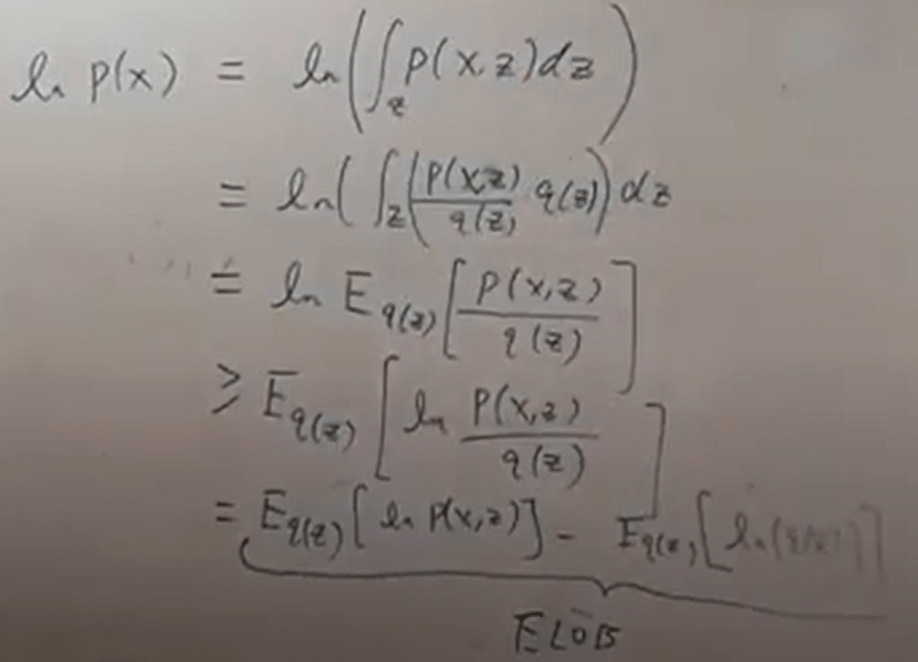
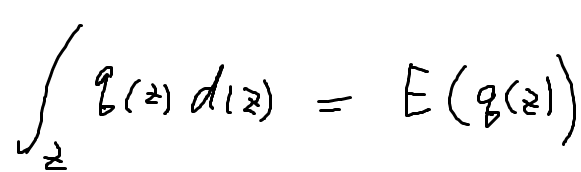

So what is expected value compared to expected maximum symbol?


Then need to maximize ELOB.