I collected three papers on LDA Application in Financial Analysis, aiming to learn or reference from others what I have been bogged down – to make sense of bunch of words created by LDA and put into actual usage.
The three papers are: Do Fraudulent Firms Produce Abnormal Disclosure? authored by Gerard Hoberg* and Craig Lewis∗ April 20, 2015, What are You Saying? Using topic to Detect Financial Misreporting∗ Nerissa C. Brown Associate Professor University of Illinois nerissab@illinois.edu Richard M. Crowley Assistant Professor Singapore Management University rcrowley@smu.edu.sg W. Brooke Elliott Ernst & Young Distinguished Professor University of Illinois wbe@illinois.edu November 2019 and Analyst Information Discovery and Interpretation Roles: A Topic Modeling Approach Allen Huang Hong Kong University of Science & Technology Department of Accounting Amy Zang Hong Kong University of Science & Technology Department of Accounting This work cannot be used without the author’s permission. This paper can be downloaded without charge from the Social Sciences Research Network Electronic Paper Collection: http://ssrn.com/abstract=2409482 UNIVERSITY OF MICHIGAN Reuven Lehavy Stephen M. Ross School of Business University of Michigan Rong Zheng Hong Kong University of Science & Technology Business Statistics and Operations Management Working Paper No. 1229 November 2016.
The hypothesis of the first paper includes 1. fraudulent companies disclose fewer details explaining their performance; 2. fraudulent firms grandstand the manipulated performance itself; 3. managers tend to disassociate themselves from the fraudulent disclosure during years the firm is engaged in fraud. Unfortunately I went through back and forth and can’t find any details about how the LDA is applied in reaching to statistics analysis in the paper.
The second paper “Using a Bayesian topic modeling algorithm, we determine and empirically quantify the topic content of a large collection of 10-K narratives spanning 1994 to 2012. We find that the algorithm produces a valid set of semantically meaningful topics that predict financial misreporting, based on samples of SEC enforcement actions (AAERs) and irregularities identified from financial restatements and 10-K filing amendments.”. The detailed approach using LDA is “draw the filings in each batch in random order to mitigate overweighting of early years in the online LDA tool. We then set the algorithm to identify 31 topics in each five-year window. We select 31 topics since simulated results indicate that this number of topics is optimal in detecting irregularities drawn from amended 10-K filings.15 We run the LDA…”; “we aggregate the topics discovered in each window up to the full sample. We refer to the aggregate topics as “combined topics.” We allow multiple topics within a given window to be associated with the same combined topic. We also allow the number of combined topics to exceed 31, as some topics do not appear in every window. We derive the combined topics by matching topics across years based on the Pearson correlation of the word weights within the topics. All topics with a Pearson correlation above a specific threshold are grouped together”, “We construct the list by first extracting the top 1,000 sentences per topic based on the weighted words associated with each combined topic. Next, we sort the sentences based on length and extract the middle tercile (334 sentences) as representative sentences of typical length. The 20 most frequent bigrams (two-word phrases excluding stop words, numbers, and symbols) are then extracted from the 334 mid-length sentences. These sentences are also sorted based on the cosine similarity between a given sentence and the remaining 333 sentences. We manually review the top 20 bigrams and top 100 mid-length sentences based on cosine similarity, and assign descriptive labels to each of the combined topics.”. What they found “e LDA algorithm performs well in identifying narrative content that relates distinctively to changes in firms’ financial performance and their financing activities”; Other performance and financing-related topics include segment performance, debt issuances and credit arrangements, also identifies topics related to complex business transactions such as hedging activities; Then measure is taken as
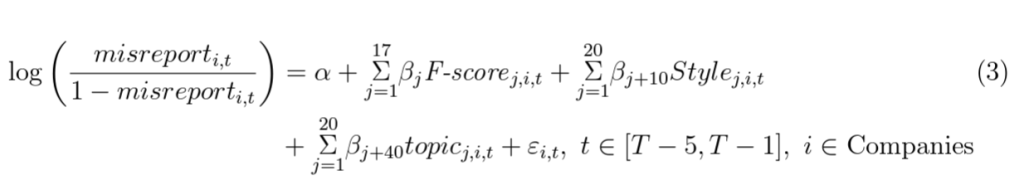
“For each prediction year, we present green (red) boxes if at least one subtopic for a given combined topic loads as positive (negative) and significant at the 10% level or greater, and all other subtopics are insignificant. We code the boxes as gray (“Other”) if all subtopics for a given combined topic are insignificant, if multiple subtopics are significant but with opposing signs, or if all subtopics are dropped from the regression due to multicollinearity.”
The question from this paper I have is what is the metric in differentiating these 31 some topics from negative and positive?
The third paper tried to find how financial analysts serve their information intermediary role by conducting a large-scale comparison of the textual content of analyst research reports to that of closely preceding corporate disclosures. LDA is used here to assist comparing the thematic content between two bodies of large texts/reports. “The textual comparison allows us to investigate the following questions: (1) What type of information do analysts provide in prompt reports? (2) Do analyst discussions of new topics and of conference call topics provide incremental value to investors? And (3) under what conditions do analyst reports provide more value to investors?”

The choice of the values of and depends on the specific textual genre, the number of topics and the vocabulary size. We choose values of 0.1 and 0.01 for and , respectively, based on the recommended values in the literature (Steyvers and Griffiths 2006; Kaplan and Vakili 2015).


