The problem is formulated as

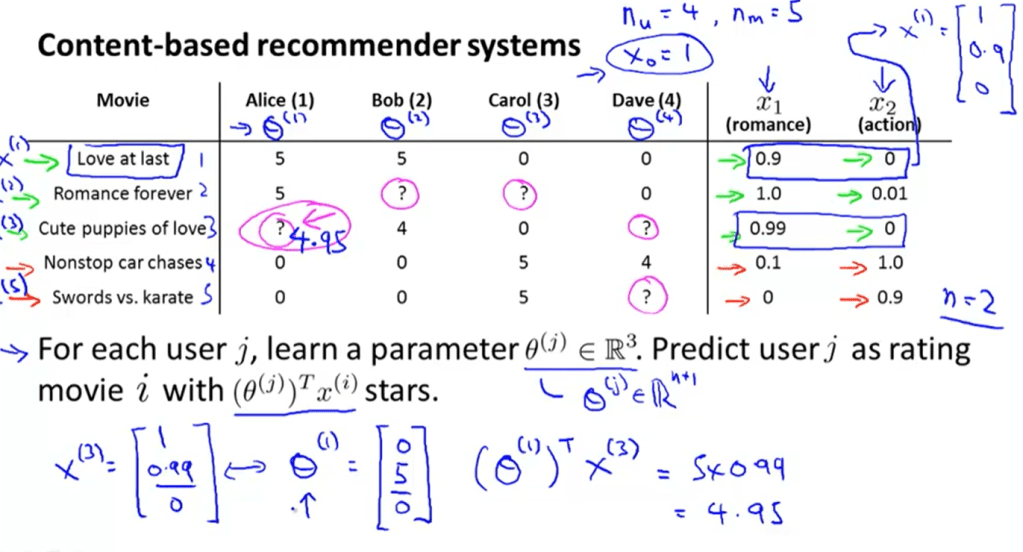
The clever part is to introduce the x1, x3 features – content based features – and apply each one with specific theta parameters.

Since it’s hard to obtain the features of each movie, but we can collect the parameter of theta per reviewer, inferring the features then. Hence reviewers collaboratively help estimate features.
Vectorization Low Rank Matrix Factorization is just to express the computation in matrix form, it’s a low rank matrix.
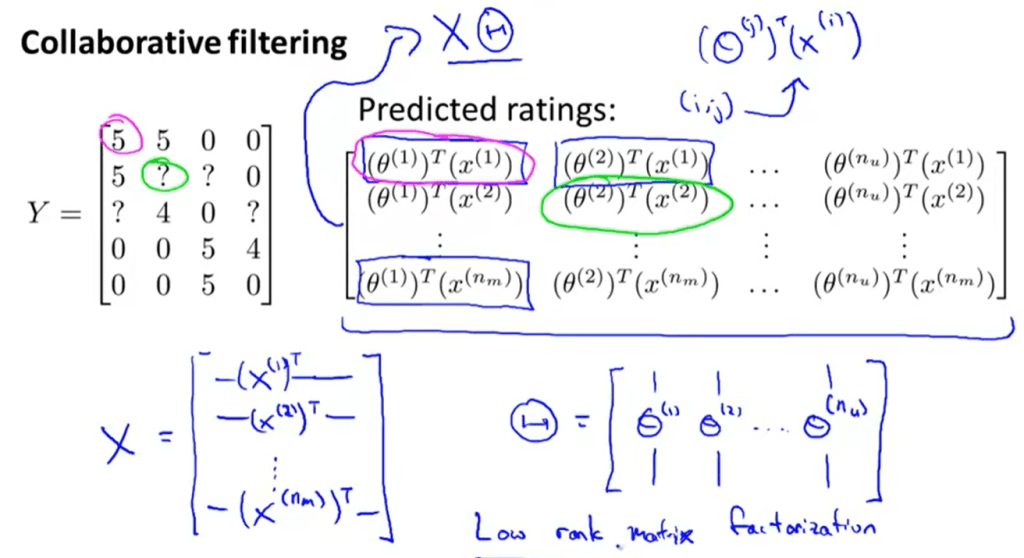
This chapter already is deeply applied in all walks of life such as Amazon recommending similar product, or Spotify recommending related music to users. So if we can know movie/product feature parameter vectors, then calculate the distance between the two vectors, we know what we can recommend.

Implementational Detail Mean Normalization for users who haven’t given any ratings/info, what does the algorithm do then? Unanimously apply zero to this user is not feasible, the best approach is compute the mean/average each row/movie, and feed into the algorithm for the unknown user.
