Every word is represented by on-hot representation, but the key is embedding, which is to featurize them.
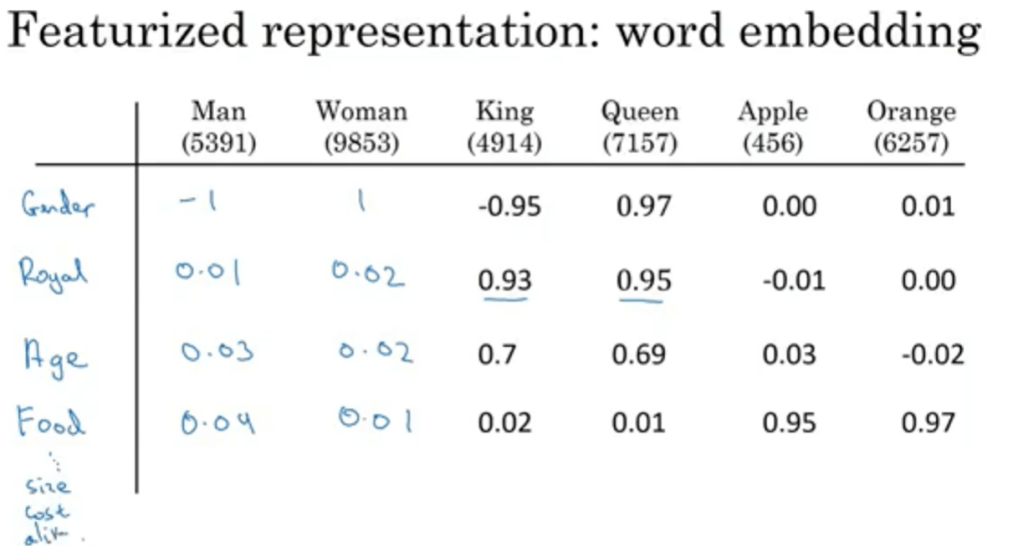
It’s realized by t-distributed stochastic neighbor embedding (t-SNE) technique, which is a statistical method for visualizing high-dimensional data by giving each data point a location in a two or three-dimensional map. 100 billions of unlabeled corpse are examined by t-SNE to embed all words you know. So if you have a text, which a word j in it, the computation of matrix multiplying one-hot representation is conducted to extract the embedding of this word:

Given context, then you can apply neural model to predict the target word as illustrated below
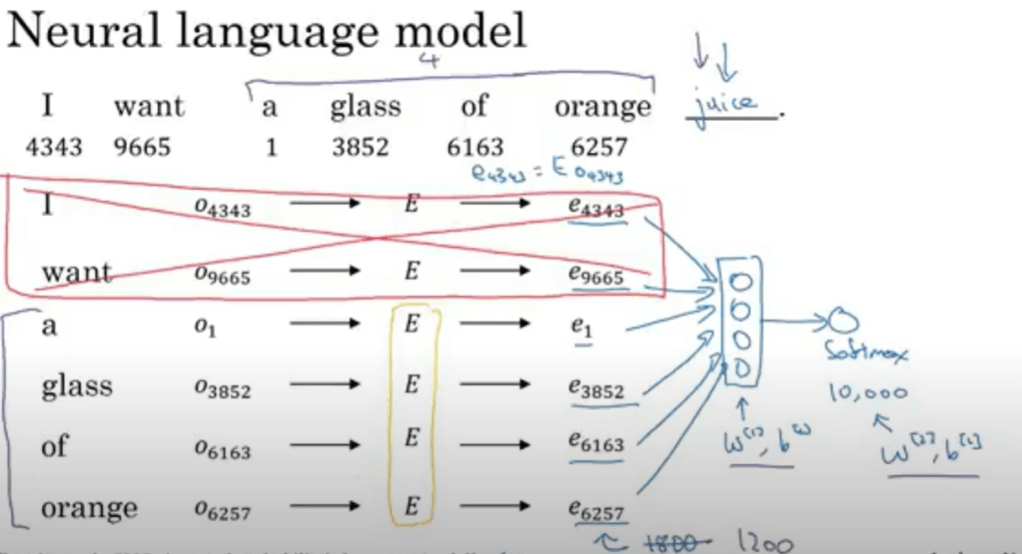
This word embedding, or word featurization, is also frequently referred to as word2vec. There are mainly skip-gram and cbow (continuous bag of words), GloVes models in word2vec.
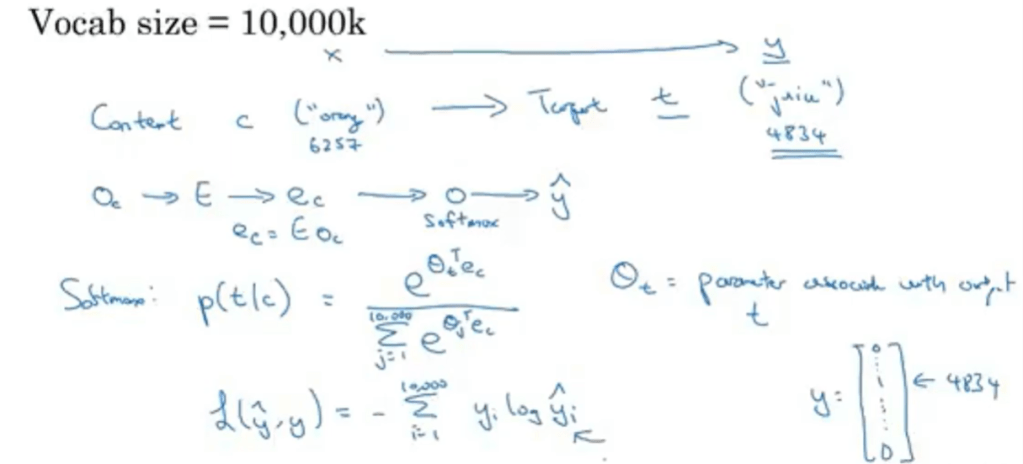
To overcome the computation speed issue, hierarchy softmax and negative sampling is applied. What is negative sampling? Instead of going across the whole large dataset, only pick a few items, mostly negative sample to train a context-target word.

GloVe, coined from Global Vectors, is a model for distributed word representation. The model is an unsupervised learning algorithm for obtaining vector representations for words. This is achieved by mapping words into a meaningful space where the distance between words is related to semantic similarity.

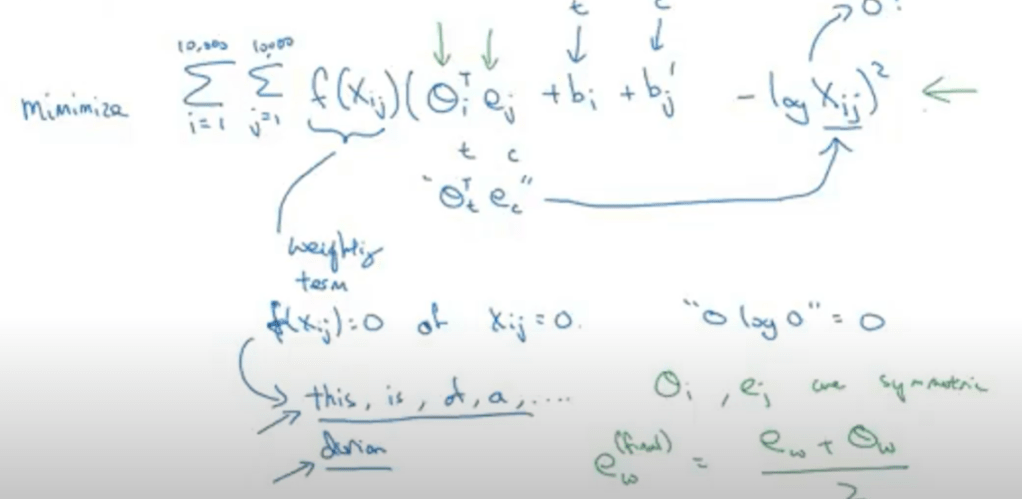
Glove cleverly applied vector difference to highlight word senses:


