this is the course 1-2 parts.
The math of simple logistic regression is outlined as below

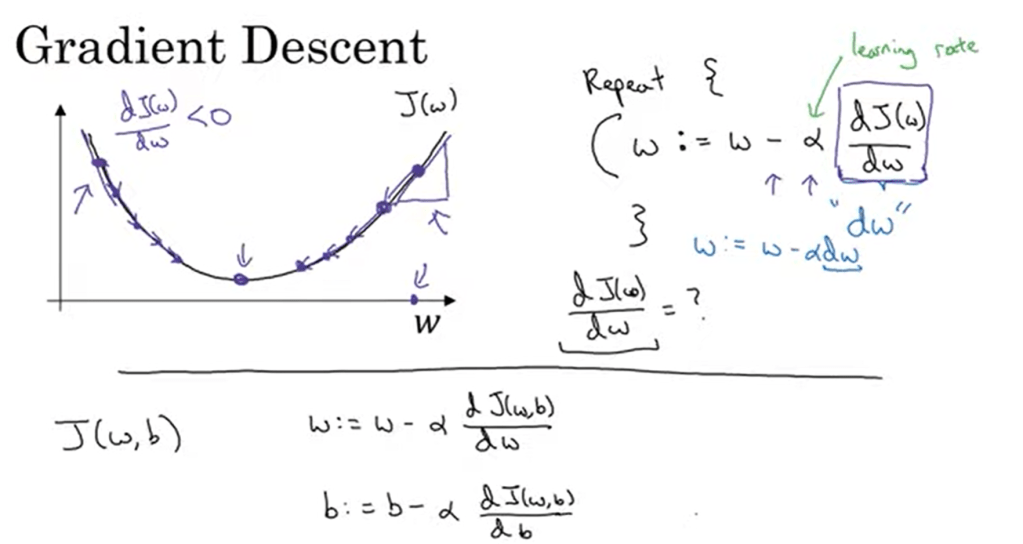
In applying gradient descent, you can use exponentially weighted average technique, or RMSProp to accelerate the optimization algorithm.
Adam Optimization Algorithm combines both exponentially weighted average and RMSProp.
Learning rate should be adjusted too:

In applying DL, you need to Tune Hyperparameters, the Process can be better to be done in random rather than in grid.
Normalizing Activations in a Network, called batch norm.
