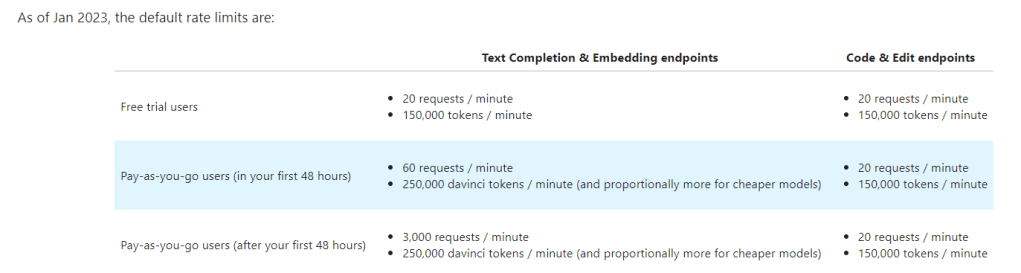
rate limit is set as
How to avoid rate limit: retrying with exponential backoff, Tenacity library or backoff library can be used. This is suitable when processing real-time requests from users, backoff and retry is a great strategy to minimize latency while avoiding rate limit errors
How to maximize throughput of batch processing given rate limits when large volumes of batch data, where throughput matters more than latency, there are a few other things you can do in addition to backoff and retry.
We need to Proactively adding delay between requests. there is a sample adding delay to a request sample code.
The OpenAI API has separate limits for requests per minute and tokens per minute. Sending in a batch of prompts works exactly the same as a normal API call, except that pass in a list of strings to prompt parameter instead of a single string. Note to use index filed to ensure sequence and object matched.
Example parallel processing script
We’ve written an example script for parallel processing large quantities of API requests: api_request_parallel_processor.py.
The script combines some handy features:
- Streams requests from file, to avoid running out of memory for giant jobs
- Makes requests concurrently, to maximize throughput
- Throttles both request and token usage, to stay under rate limits
- Retries failed requests, to avoid missing data
- Logs errors, to diagnose problems with requests
