How is TDA applied in Deep Learning? In Bei Wang’s lecture, it’s about interpretability of deep learning.
First to understand in neural network, what is layer? In the context of neural networks, a “layer” refers to a collection of neurons (or units) that process data in a specific way. Neural networks are composed of multiple such layers, each serving a unique role in transforming and processing the input data to ultimately produce a meaningful output. Each neuron in this layer corresponds to a feature in the input data, they have activation functions like ReLU, sigmoid, or tanh.
TDA in DL capture topological structures such as branches and loops in the space of activations (with high dimensions of data point – cloud points) that are hard to detect via dimensionality reduction techniques like PCA or SNE.
In the image classifier below it’s illustrative as how point cloud turned into mapper graph as a topological summary, capturing key features of objects and sensible to viewer.
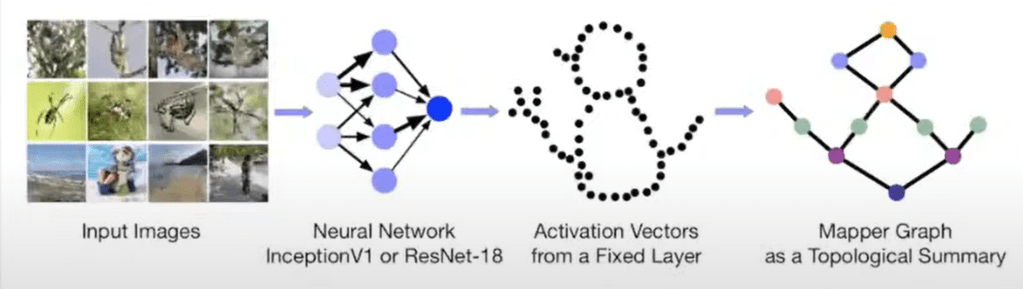
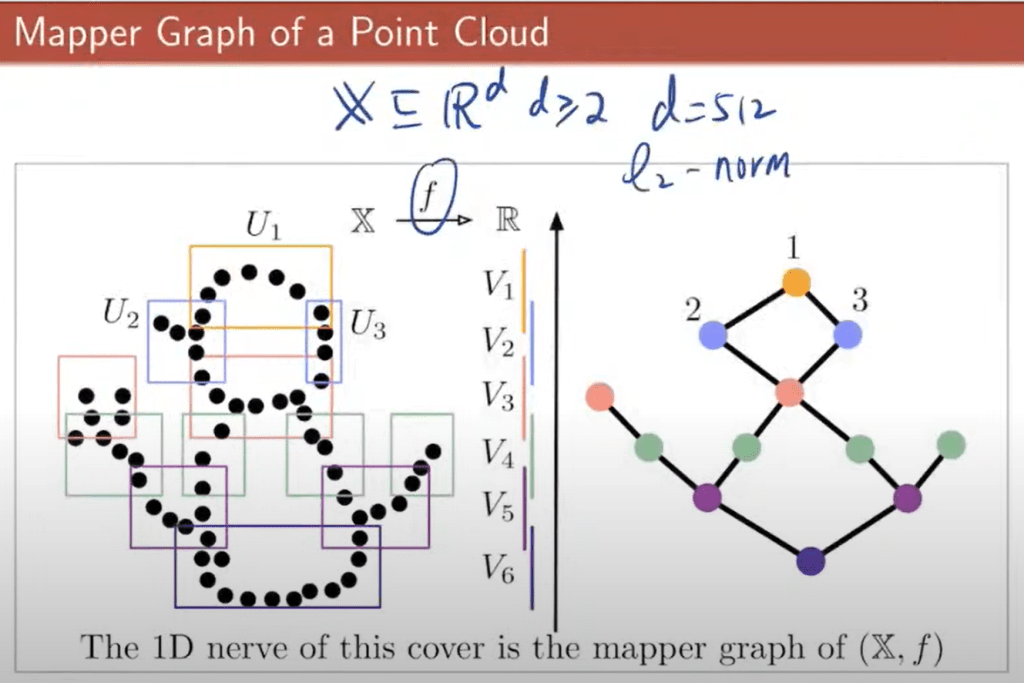
As the process or how graph mapper works:
In real cases such as recognizing cars, wheel and tread features: Higher layers might integrate these intermediate features to recognize a wheel-tread combination as a single, more complex feature. Early layers might capture basic features such as lines and curves. Intermediate layers could recognize shapes resembling parts of a wheel or tread pattern.
Certain features often co-occur, and neural networks are good at capturing these correlations. For example: Wheels and Treads: In many images (e.g., vehicles, machinery), wheels and treads often appear together. The network learns this co-occurrence and may represent these features jointly in higher layers.

