"""
you give this script some words (one per line) and it will generate more things like it.
uses super state of the art Transformer AI tech
this code is intended to be super hackable. tune it to your needs.
Changes from minGPT:
- I removed the from_pretrained function where we init with GPT2 weights
- I removed dropout layers because the models we train here are small,
it's not necessary to understand at this stage and at this scale.
- I removed weight decay and all of the complexity around what parameters are
and are not weight decayed. I don't believe this should make a massive
difference at the scale that we operate on here.
"""
import os
import sys
import time
import math
import argparse
from dataclasses import dataclass
from typing import List
import torch
import torch.nn as nn
from torch.nn import functional as F
from torch.utils.data import Dataset
from torch.utils.data.dataloader import DataLoader
from torch.utils.tensorboard import SummaryWriter
# -----------------------------------------------------------------------------
@dataclass
class ModelConfig:
block_size: int = None # length of the input sequences of integers
vocab_size: int = None # the input integers are in range [0 .. vocab_size -1]
# parameters below control the sizes of each model slightly differently
n_layer: int = 4
n_embd: int = 64
n_embd2: int = 64
n_head: int = 4
# -----------------------------------------------------------------------------
# Transformer Language Model (*exactly* as used in GPT-2)
class NewGELU(nn.Module):
"""
Implementation of the GELU activation function currently in Google BERT repo (identical to OpenAI GPT).
Reference: Gaussian Error Linear Units (GELU) paper: https://arxiv.org/abs/1606.08415
"""
def forward(self, x):
return 0.5 * x * (1.0 + torch.tanh(math.sqrt(2.0 / math.pi) * (x + 0.044715 * torch.pow(x, 3.0))))
class CausalSelfAttention(nn.Module):
"""
A vanilla multi-head masked self-attention layer with a projection at the end.
It is possible to use torch.nn.MultiheadAttention here but I am including an
explicit implementation here to show that there is nothing too scary here.
"""
def __init__(self, config):
super().__init__()
assert config.n_embd % config.n_head == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd)
# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd)
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
self.n_head = config.n_head
self.n_embd = config.n_embd
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k ,v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
# output projection
y = self.c_proj(y)
return y
class Block(nn.Module):
""" an unassuming Transformer block """
def __init__(self, config):
super().__init__()
self.ln_1 = nn.LayerNorm(config.n_embd)
self.attn = CausalSelfAttention(config)
self.ln_2 = nn.LayerNorm(config.n_embd)
self.mlp = nn.ModuleDict(dict(
c_fc = nn.Linear(config.n_embd, 4 * config.n_embd),
c_proj = nn.Linear(4 * config.n_embd, config.n_embd),
act = NewGELU(),
))
m = self.mlp
self.mlpf = lambda x: m.c_proj(m.act(m.c_fc(x))) # MLP forward
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlpf(self.ln_2(x))
return x
class Transformer(nn.Module):
""" Transformer Language Model, exactly as seen in GPT-2 """
def __init__(self, config):
super().__init__()
self.block_size = config.block_size
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = nn.LayerNorm(config.n_embd),
))
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
# report number of parameters (note we don't count the decoder parameters in lm_head)
n_params = sum(p.numel() for p in self.transformer.parameters())
print("number of parameters: %.2fM" % (n_params/1e6,))
def get_block_size(self):
return self.block_size
def forward(self, idx, targets=None):
device = idx.device
b, t = idx.size()
assert t <= self.block_size, f"Cannot forward sequence of length {t}, block size is only {self.block_size}"
pos = torch.arange(0, t, dtype=torch.long, device=device).unsqueeze(0) # shape (1, t)
# forward the GPT model itself
tok_emb = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (1, t, n_embd)
x = tok_emb + pos_emb
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
logits = self.lm_head(x)
# if we are given some desired targets also calculate the loss
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
return logits, loss
# -----------------------------------------------------------------------------
# Bag of Words (BoW) language model
class CausalBoW(nn.Module):
"""
Causal bag of words. Averages the preceding elements and looks suspiciously like
a CausalAttention module you'd find in a transformer, for no apparent reason at all ;)
"""
def __init__(self, config):
super().__init__()
# used to mask out vectors and preserve autoregressive property
self.block_size = config.block_size
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, config.block_size, config.block_size))
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, n_embd
# do the weighted average of all preceeding token features
att = torch.zeros((B, T, T), device=x.device)
att = att.masked_fill(self.bias[:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
y = att @ x # (B, T, T) x (B, T, C) -> (B, T, C)
return y
class BoWBlock(nn.Module):
""" collects BoW features and adds an MLP """
def __init__(self, config):
super().__init__()
# Causal BoW module
self.cbow = CausalBoW(config)
# MLP assembler
self.mlp = nn.ModuleDict(dict(
c_fc = nn.Linear(config.n_embd, config.n_embd2),
c_proj = nn.Linear(config.n_embd2, config.n_embd),
))
m = self.mlp
self.mlpf = lambda x: m.c_proj(F.tanh(m.c_fc(x))) # MLP forward
def forward(self, x):
x = x + self.cbow(x)
x = x + self.mlpf(x)
return x
class BoW(nn.Module):
"""
takes the previous block_size tokens, encodes them with a lookup table,
also encodes their positions with lookup table, then averages all of those
embeddings up and uses that to predict the next token.
"""
def __init__(self, config):
super().__init__()
self.block_size = config.block_size
self.vocab_size = config.vocab_size
# token embedding
self.wte = nn.Embedding(config.vocab_size, config.n_embd)
# position embedding
self.wpe = nn.Embedding(config.block_size, config.n_embd)
# context block
self.context_block = BoWBlock(config)
# language model head decoder layer
self.lm_head = nn.Linear(config.n_embd, self.vocab_size)
def get_block_size(self):
return self.block_size
def forward(self, idx, targets=None):
device = idx.device
b, t = idx.size()
assert t <= self.block_size, f"Cannot forward sequence of length {t}, block size is only {self.block_size}"
pos = torch.arange(0, t, dtype=torch.long, device=device).unsqueeze(0) # shape (1, t)
# forward the token and position embedding layers
tok_emb = self.wte(idx) # token embeddings of shape (b, t, n_embd)
pos_emb = self.wpe(pos) # position embeddings of shape (1, t, n_embd)
# add and run through the decoder MLP
x = tok_emb + pos_emb
# run the bag of words context module
x = self.context_block(x)
# decode to next token probability
logits = self.lm_head(x)
# if we are given some desired targets also calculate the loss
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
return logits, loss
# -----------------------------------------------------------------------------
"""
Recurrent Neural Net language model: either a vanilla RNN recurrence or a GRU.
Did not implement an LSTM because its API is a bit more annoying as it has
both a hidden state and a cell state, but it's very similar to GRU and in
practice works just as well.
"""
class RNNCell(nn.Module):
"""
the job of a 'Cell' is to:
take input at current time step x_{t} and the hidden state at the
previous time step h_{t-1} and return the resulting hidden state
h_{t} at the current timestep
"""
def __init__(self, config):
super().__init__()
self.xh_to_h = nn.Linear(config.n_embd + config.n_embd2, config.n_embd2)
def forward(self, xt, hprev):
xh = torch.cat([xt, hprev], dim=1)
ht = F.tanh(self.xh_to_h(xh))
return ht
class GRUCell(nn.Module):
"""
same job as RNN cell, but a bit more complicated recurrence formula
that makes the GRU more expressive and easier to optimize.
"""
def __init__(self, config):
super().__init__()
# input, forget, output, gate
self.xh_to_z = nn.Linear(config.n_embd + config.n_embd2, config.n_embd2)
self.xh_to_r = nn.Linear(config.n_embd + config.n_embd2, config.n_embd2)
self.xh_to_hbar = nn.Linear(config.n_embd + config.n_embd2, config.n_embd2)
def forward(self, xt, hprev):
# first use the reset gate to wipe some channels of the hidden state to zero
xh = torch.cat([xt, hprev], dim=1)
r = F.sigmoid(self.xh_to_r(xh))
hprev_reset = r * hprev
# calculate the candidate new hidden state hbar
xhr = torch.cat([xt, hprev_reset], dim=1)
hbar = F.tanh(self.xh_to_hbar(xhr))
# calculate the switch gate that determines if each channel should be updated at all
z = F.sigmoid(self.xh_to_z(xh))
# blend the previous hidden state and the new candidate hidden state
ht = (1 - z) * hprev + z * hbar
return ht
class RNN(nn.Module):
def __init__(self, config, cell_type):
super().__init__()
self.block_size = config.block_size
self.vocab_size = config.vocab_size
self.start = nn.Parameter(torch.zeros(1, config.n_embd2)) # the starting hidden state
self.wte = nn.Embedding(config.vocab_size, config.n_embd) # token embeddings table
if cell_type == 'rnn':
self.cell = RNNCell(config)
elif cell_type == 'gru':
self.cell = GRUCell(config)
self.lm_head = nn.Linear(config.n_embd2, self.vocab_size)
def get_block_size(self):
return self.block_size
def forward(self, idx, targets=None):
device = idx.device
b, t = idx.size()
# embed all the integers up front and all at once for efficiency
emb = self.wte(idx) # (b, t, n_embd)
# sequentially iterate over the inputs and update the RNN state each tick
hprev = self.start.expand((b, -1)) # expand out the batch dimension
hiddens = []
for i in range(t):
xt = emb[:, i, :] # (b, n_embd)
ht = self.cell(xt, hprev) # (b, n_embd2)
hprev = ht
hiddens.append(ht)
# decode the outputs
hidden = torch.stack(hiddens, 1) # (b, t, n_embd2)
logits = self.lm_head(hidden)
# if we are given some desired targets also calculate the loss
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
return logits, loss
# -----------------------------------------------------------------------------
# MLP language model
class MLP(nn.Module):
"""
takes the previous block_size tokens, encodes them with a lookup table,
concatenates the vectors and predicts the next token with an MLP.
Reference:
Bengio et al. 2003 https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
"""
def __init__(self, config):
super().__init__()
self.block_size = config.block_size
self.vocab_size = config.vocab_size
self.wte = nn.Embedding(config.vocab_size + 1, config.n_embd) # token embeddings table
# +1 in the line above for a special <BLANK> token that gets inserted if encoding a token
# before the beginning of the input sequence
self.mlp = nn.Sequential(
nn.Linear(self.block_size * config.n_embd, config.n_embd2),
nn.Tanh(),
nn.Linear(config.n_embd2, self.vocab_size)
)
def get_block_size(self):
return self.block_size
def forward(self, idx, targets=None):
# gather the word embeddings of the previous 3 words
embs = []
for k in range(self.block_size):
tok_emb = self.wte(idx) # token embeddings of shape (b, t, n_embd)
idx = torch.roll(idx, 1, 1)
idx[:, 0] = self.vocab_size # special <BLANK> token
embs.append(tok_emb)
# concat all of the embeddings together and pass through an MLP
x = torch.cat(embs, -1) # (b, t, n_embd * block_size)
logits = self.mlp(x)
# if we are given some desired targets also calculate the loss
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
return logits, loss
# -----------------------------------------------------------------------------
# Bigram language model
class Bigram(nn.Module):
"""
Bigram Language Model 'neural net', simply a lookup table of logits for the
next character given a previous character.
"""
def __init__(self, config):
super().__init__()
n = config.vocab_size
self.logits = nn.Parameter(torch.zeros((n, n)))
def get_block_size(self):
return 1 # this model only needs one previous character to predict the next
def forward(self, idx, targets=None):
# 'forward pass', lol
logits = self.logits[idx]
# if we are given some desired targets also calculate the loss
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
return logits, loss
# -----------------------------------------------------------------------------
# helper functions for evaluating and sampling from the model
@torch.no_grad()
def generate(model, idx, max_new_tokens, temperature=1.0, do_sample=False, top_k=None):
"""
Take a conditioning sequence of indices idx (LongTensor of shape (b,t)) and complete
the sequence max_new_tokens times, feeding the predictions back into the model each time.
Most likely you'll want to make sure to be in model.eval() mode of operation for this.
"""
block_size = model.get_block_size()
for _ in range(max_new_tokens):
# if the sequence context is growing too long we must crop it at block_size
idx_cond = idx if idx.size(1) <= block_size else idx[:, -block_size:]
# forward the model to get the logits for the index in the sequence
logits, _ = model(idx_cond)
# pluck the logits at the final step and scale by desired temperature
logits = logits[:, -1, :] / temperature
# optionally crop the logits to only the top k options
if top_k is not None:
v, _ = torch.topk(logits, top_k)
logits[logits < v[:, [-1]]] = -float('Inf')
# apply softmax to convert logits to (normalized) probabilities
probs = F.softmax(logits, dim=-1)
# either sample from the distribution or take the most likely element
if do_sample:
idx_next = torch.multinomial(probs, num_samples=1)
else:
_, idx_next = torch.topk(probs, k=1, dim=-1)
# append sampled index to the running sequence and continue
idx = torch.cat((idx, idx_next), dim=1)
return idx
def print_samples(num=10):
""" samples from the model and pretty prints the decoded samples """
X_init = torch.zeros(num, 1, dtype=torch.long).to(args.device)
top_k = args.top_k if args.top_k != -1 else None
steps = train_dataset.get_output_length() - 1 # -1 because we already start with <START> token (index 0)
X_samp = generate(model, X_init, steps, top_k=top_k, do_sample=True).to('cpu')
train_samples, test_samples, new_samples = [], [], []
for i in range(X_samp.size(0)):
# get the i'th row of sampled integers, as python list
row = X_samp[i, 1:].tolist() # note: we need to crop out the first <START> token
# token 0 is the <STOP> token, so we crop the output sequence at that point
crop_index = row.index(0) if 0 in row else len(row)
row = row[:crop_index]
word_samp = train_dataset.decode(row)
# separately track samples that we have and have not seen before
if train_dataset.contains(word_samp):
train_samples.append(word_samp)
elif test_dataset.contains(word_samp):
test_samples.append(word_samp)
else:
new_samples.append(word_samp)
print('-'*80)
for lst, desc in [(train_samples, 'in train'), (test_samples, 'in test'), (new_samples, 'new')]:
print(f"{len(lst)} samples that are {desc}:")
for word in lst:
print(word)
print('-'*80)
@torch.inference_mode()
def evaluate(model, dataset, batch_size=50, max_batches=None):
model.eval()
loader = DataLoader(dataset, shuffle=True, batch_size=batch_size, num_workers=0)
losses = []
for i, batch in enumerate(loader):
batch = [t.to(args.device) for t in batch]
X, Y = batch
logits, loss = model(X, Y)
losses.append(loss.item())
if max_batches is not None and i >= max_batches:
break
mean_loss = torch.tensor(losses).mean().item()
model.train() # reset model back to training mode
return mean_loss
# -----------------------------------------------------------------------------
# helper functions for creating the training and test Datasets that emit words
class CharDataset(Dataset):
def __init__(self, words, chars, max_word_length):
self.words = words
self.chars = chars
self.max_word_length = max_word_length
self.stoi = {ch:i+1 for i,ch in enumerate(chars)}
self.itos = {i:s for s,i in self.stoi.items()} # inverse mapping
def __len__(self):
return len(self.words)
def contains(self, word):
return word in self.words
def get_vocab_size(self):
return len(self.chars) + 1 # all the possible characters and special 0 token
def get_output_length(self):
return self.max_word_length + 1 # <START> token followed by words
def encode(self, word):
ix = torch.tensor([self.stoi[w] for w in word], dtype=torch.long)
return ix
def decode(self, ix):
word = ''.join(self.itos[i] for i in ix)
return word
def __getitem__(self, idx):
word = self.words[idx]
ix = self.encode(word)
x = torch.zeros(self.max_word_length + 1, dtype=torch.long)
y = torch.zeros(self.max_word_length + 1, dtype=torch.long)
x[1:1+len(ix)] = ix
y[:len(ix)] = ix
y[len(ix)+1:] = -1 # index -1 will mask the loss at the inactive locations
return x, y
def create_datasets(input_file):
# preprocessing of the input text file
with open(input_file, 'r') as f:
data = f.read()
words = data.splitlines()
words = [w.strip() for w in words] # get rid of any leading or trailing white space
words = [w for w in words if w] # get rid of any empty strings
chars = sorted(list(set(''.join(words)))) # all the possible characters
max_word_length = max(len(w) for w in words)
print(f"number of examples in the dataset: {len(words)}")
print(f"max word length: {max_word_length}")
print(f"number of unique characters in the vocabulary: {len(chars)}")
print("vocabulary:")
print(''.join(chars))
# partition the input data into a training and the test set
test_set_size = min(1000, int(len(words) * 0.1)) # 10% of the training set, or up to 1000 examples
rp = torch.randperm(len(words)).tolist()
train_words = [words[i] for i in rp[:-test_set_size]]
test_words = [words[i] for i in rp[-test_set_size:]]
print(f"split up the dataset into {len(train_words)} training examples and {len(test_words)} test examples")
# wrap in dataset objects
train_dataset = CharDataset(train_words, chars, max_word_length)
test_dataset = CharDataset(test_words, chars, max_word_length)
return train_dataset, test_dataset
class InfiniteDataLoader:
"""
this is really hacky and I'm not proud of it, but there doesn't seem to be
a better way in PyTorch to just create an infinite dataloader?
"""
def __init__(self, dataset, **kwargs):
train_sampler = torch.utils.data.RandomSampler(dataset, replacement=True, num_samples=int(1e10))
self.train_loader = DataLoader(dataset, sampler=train_sampler, **kwargs)
self.data_iter = iter(self.train_loader)
def next(self):
try:
batch = next(self.data_iter)
except StopIteration: # this will technically only happen after 1e10 samples... (i.e. basically never)
self.data_iter = iter(self.train_loader)
batch = next(self.data_iter)
return batch
# -----------------------------------------------------------------------------
if __name__ == '__main__':
# parse command line args
parser = argparse.ArgumentParser(description="Make More")
# system/input/output
parser.add_argument('--input-file', '-i', type=str, default='names.txt', help="input file with things one per line")
parser.add_argument('--work-dir', '-o', type=str, default='out', help="output working directory")
parser.add_argument('--resume', action='store_true', help="when this flag is used, we will resume optimization from existing model in the workdir")
parser.add_argument('--sample-only', action='store_true', help="just sample from the model and quit, don't train")
parser.add_argument('--num-workers', '-n', type=int, default=4, help="number of data workers for both train/test")
parser.add_argument('--max-steps', type=int, default=-1, help="max number of optimization steps to run for, or -1 for infinite.")
parser.add_argument('--device', type=str, default='cpu', help="device to use for compute, examples: cpu|cuda|cuda:2|mps")
parser.add_argument('--seed', type=int, default=3407, help="seed")
# sampling
parser.add_argument('--top-k', type=int, default=-1, help="top-k for sampling, -1 means no top-k")
# model
parser.add_argument('--type', type=str, default='transformer', help="model class type to use, bigram|mlp|rnn|gru|bow|transformer")
parser.add_argument('--n-layer', type=int, default=4, help="number of layers")
parser.add_argument('--n-head', type=int, default=4, help="number of heads (in a transformer)")
parser.add_argument('--n-embd', type=int, default=64, help="number of feature channels in the model")
parser.add_argument('--n-embd2', type=int, default=64, help="number of feature channels elsewhere in the model")
# optimization
parser.add_argument('--batch-size', '-b', type=int, default=32, help="batch size during optimization")
parser.add_argument('--learning-rate', '-l', type=float, default=5e-4, help="learning rate")
parser.add_argument('--weight-decay', '-w', type=float, default=0.01, help="weight decay")
args = parser.parse_args()
print(vars(args))
# system inits
torch.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
os.makedirs(args.work_dir, exist_ok=True)
writer = SummaryWriter(log_dir=args.work_dir)
# init datasets
train_dataset, test_dataset = create_datasets(args.input_file)
vocab_size = train_dataset.get_vocab_size()
block_size = train_dataset.get_output_length()
print(f"dataset determined that: {vocab_size=}, {block_size=}")
# init model
config = ModelConfig(vocab_size=vocab_size, block_size=block_size,
n_layer=args.n_layer, n_head=args.n_head,
n_embd=args.n_embd, n_embd2=args.n_embd2)
if args.type == 'transformer':
model = Transformer(config)
elif args.type == 'bigram':
model = Bigram(config)
elif args.type == 'mlp':
model = MLP(config)
elif args.type == 'rnn':
model = RNN(config, cell_type='rnn')
elif args.type == 'gru':
model = RNN(config, cell_type='gru')
elif args.type == 'bow':
model = BoW(config)
else:
raise ValueError(f'model type {args.type} is not recognized')
model.to(args.device)
print(f"model #params: {sum(p.numel() for p in model.parameters())}")
if args.resume or args.sample_only: # note: if we sample-only then we also assume we are resuming
print("resuming from existing model in the workdir")
model.load_state_dict(torch.load(os.path.join(args.work_dir, 'model.pt')))
if args.sample_only:
print_samples(num=50)
sys.exit()
# init optimizer
optimizer = torch.optim.AdamW(model.parameters(), lr=args.learning_rate, weight_decay=args.weight_decay, betas=(0.9, 0.99), eps=1e-8)
# init dataloader
batch_loader = InfiniteDataLoader(train_dataset, batch_size=args.batch_size, pin_memory=True, num_workers=args.num_workers)
# training loop
best_loss = None
step = 0
while True:
t0 = time.time()
# get the next batch, ship to device, and unpack it to input and target
batch = batch_loader.next()
batch = [t.to(args.device) for t in batch]
X, Y = batch
# feed into the model
logits, loss = model(X, Y)
# calculate the gradient, update the weights
model.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# wait for all CUDA work on the GPU to finish then calculate iteration time taken
if args.device.startswith('cuda'):
torch.cuda.synchronize()
t1 = time.time()
# logging
if step % 10 == 0:
print(f"step {step} | loss {loss.item():.4f} | step time {(t1-t0)*1000:.2f}ms")
# evaluate the model
if step > 0 and step % 500 == 0:
train_loss = evaluate(model, train_dataset, batch_size=100, max_batches=10)
test_loss = evaluate(model, test_dataset, batch_size=100, max_batches=10)
writer.add_scalar("Loss/train", train_loss, step)
writer.add_scalar("Loss/test", test_loss, step)
writer.flush()
print(f"step {step} train loss: {train_loss} test loss: {test_loss}")
# save the model to disk if it has improved
if best_loss is None or test_loss < best_loss:
out_path = os.path.join(args.work_dir, "model.pt")
print(f"test loss {test_loss} is the best so far, saving model to {out_path}")
torch.save(model.state_dict(), out_path)
best_loss = test_loss
# sample from the model
if step > 0 and step % 200 == 0:
print_samples(num=10)
step += 1
# termination conditions
if args.max_steps >= 0 and step >= args.max_steps:
breakThe reference paper’s diagram
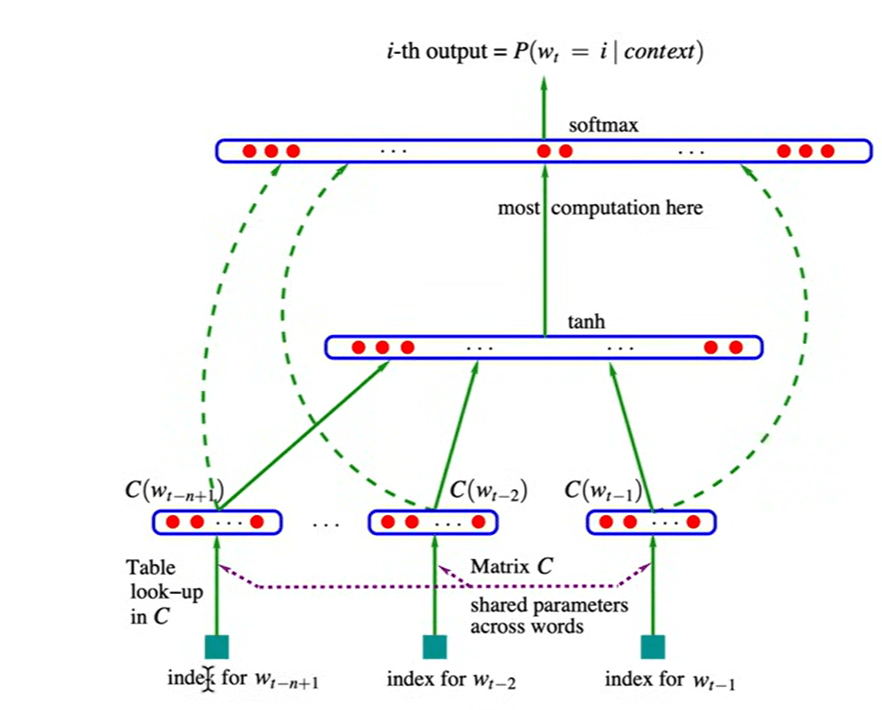
It’s necessary to know that use index number directly on embedding table is same as to look up weights from one-hot embedding, times the C look up table.
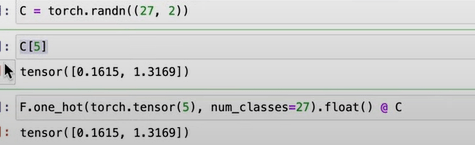
pytorch makes the tensor manipulation very easy, not only can use index number directly, times one_hot, it also can plug in 2-dimensional X directly like below
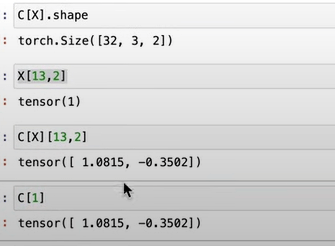
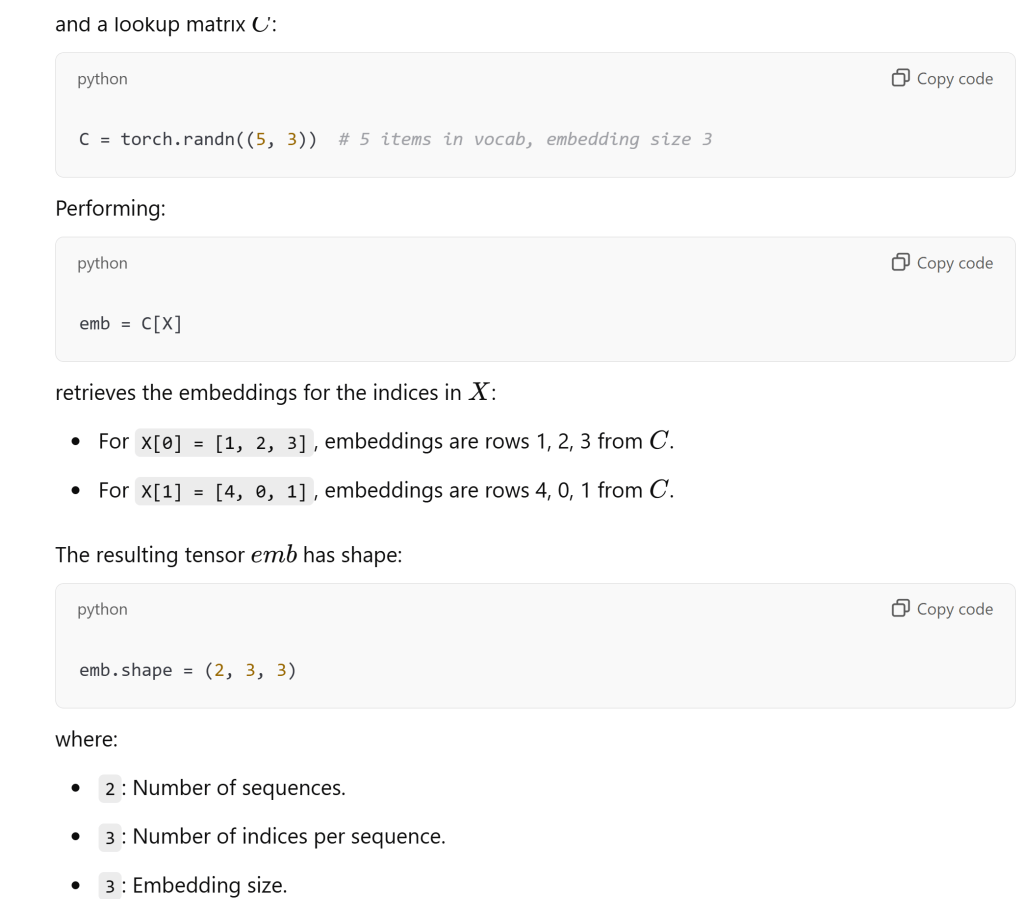
Reiterate again here as it’s super important, the concept of look up table C, original X list (2-dimensional, row is sample size, column is the block size) –> embedding table emb, a 3-D tensor, containing both X list and joined to C:
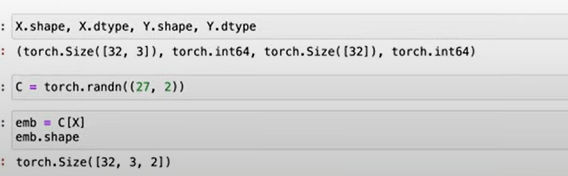
Pay great attention to sample size, block size, dimension size, neuron numbers

First, The @dataclass decorator makes it easier to create classes that are focused on storing data while handling much of the boilerplate code automatically. It leads to cleaner, more maintainable code, particularly when dealing with classes that have many attributes. this decorator automatically adds methods like __init__, __repr__ etc. so if I create config = ModelConfig(block_size=128, vocab_size=5000) print(config) # Automatically uses the __repr__ method generated by @dataclass: ModelConfig(block_size=128, vocab_size=5000, n_layer=4, n_embd=64, n_embd2=64, n_head=4).
Two, Gaussian Error Linear Units (GELU) is an activation function used in neural networks, particularly in transformers and deep learning architectures. GELU activation function currently in Google BERT repo (identical to OpenAI GPT). ts probabilistic interpretation and ability to retain information from negative inputs make it a compelling choice for activation functions in modern neural network architectures.
Third, causal self-attention is a specific type of self-attention mechanism used primarily in natural language processing (NLP) tasks, particularly in autoregressive models like the Transformer architecture.
In Causal Self Attention, Understanding Key, Query, and Value Projections
Values (VVV): These are the actual data that will be weighted and summed based on the attention scores derived from the queries and keys. The output of the attention mechanism will be a weighted sum of the values.
Queries (QQQ): These represent the current input for which we are trying to compute attention. They are used to query the keys to determine how much focus to give to each part of the input sequence.
Keys (KKK): These represent the input data that will be compared against the queries. Each key is associated with an input token, and the attention scores are calculated based on how similar the queries are to the keys.
In his jupyter notebook, the original codes are stored
# build the dataset
block_size = 3 # context length: how many characters do we take to predict the next one?
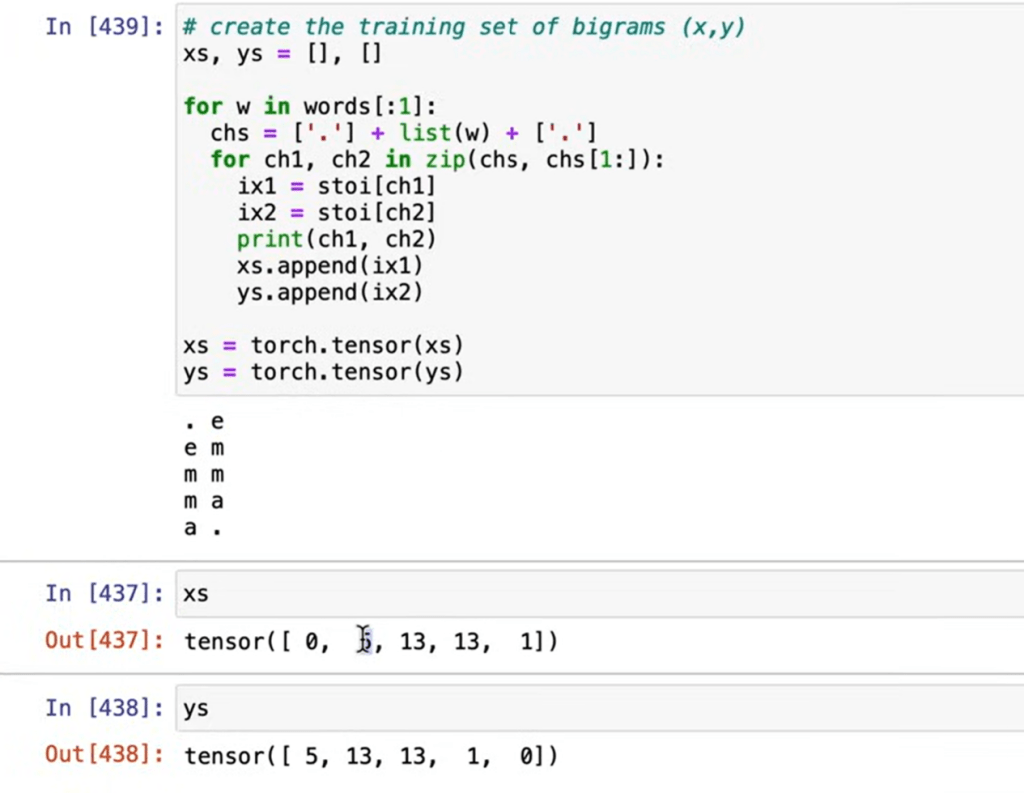
def build_dataset(words):
X, Y = [], []
for w in words:
#print(w)
context = [0] * block_size
for ch in w + '.':
ix = stoi[ch]
X.append(context)
Y.append(ix)
#print(''.join(itos[i] for i in context), '--->', itos[ix])
context = context[1:] + [ix] # crop and append
X = torch.tensor(X)
Y = torch.tensor(Y)
print(X.shape, Y.shape)
return X, YThis function creates a dataset of input-output pairs for training a character-level sequence model (like a language model). It trains the model to predict the next character in a sequence based on the given context.
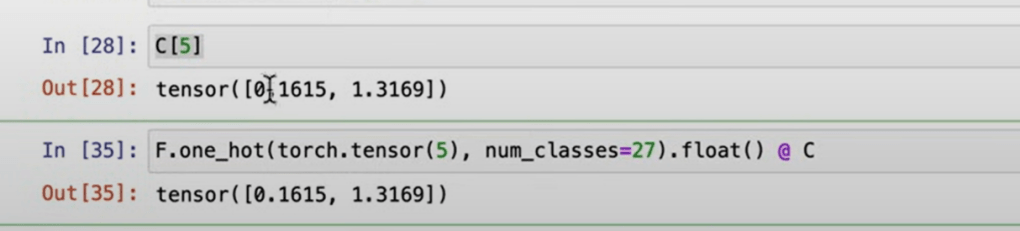
C = torch.randn((27, 2)) emb=C[X], emb.shape?
note C is the look up matrix, use index number 5 to extract the the row is equivalent to use one_hot code.
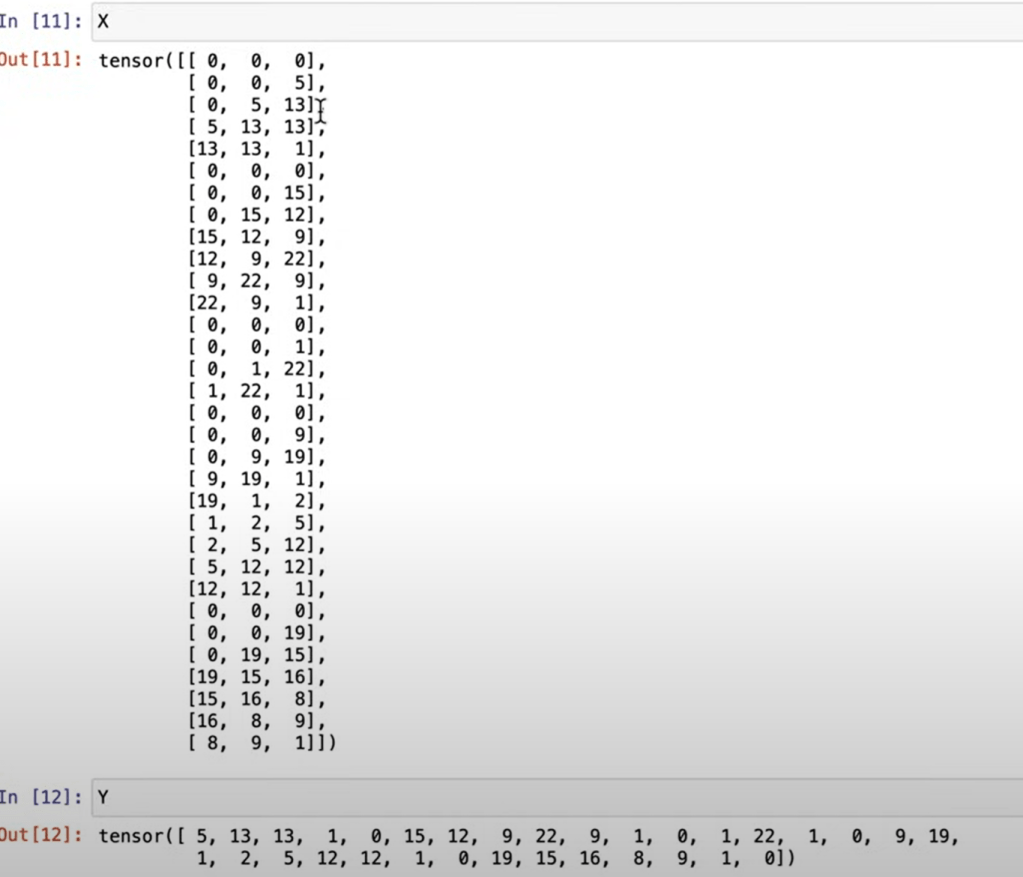
note block size in this case the number of characters as context, batch size is different, which is the number of samples in whole dataset.
C.shape=(27,2), X.shape = (N, block_size), emb.shape = (N, block_size, 2), the case in Andrej’s video, emma as example:
What is Batchnorm? Batch Normalization (BatchNorm) is a technique used in deep learning to improve the training process of neural networks. It normalizes the inputs to each layer during training, which helps stabilize and accelerate the learning process.
A Convolutional Neural Network (CNN) is a type of deep learning model specifically designed for processing grid-like data, such as images. Its primary strength lies in its ability to automatically and efficiently extract important features from the data (e.g., edges, textures, shapes) without requiring manual feature engineering.
According to Andrej, convolution is a “for loop”, allowing us to forward Linear layers efficiently over space
In the later part, he explain/demo how to adjust learning rate, plot and identify the best learning rate in this particular example is 0.1. And learning decay is commonly used too.
Data should be split to training, validation and test sets, the validation set is to tune the hyper parameters.
