Diana Hu did a great job summarizing the key innovations or ingenuities of Deepseek.
First, float 8 format to save memory without sacrificing performance.


But FP8 will have accumulation precision issue, the strategy to improve accumulation precision in FP8 GEMM operations on NVIDIA H800 GPUs. Due to limited 14-bit precision in Tensor Cores, large matrix operations (e.g., K=4096K = 4096K=4096) suffer from ~2% error. To mitigate this, intermediate results are first accumulated in Tensor Cores. After an interval (NCN_CNC), they are transferred to FP32 registers in CUDA Cores, where full-precision FP32 accumulation is performed, enhancing accuracy while maintaining efficiency.
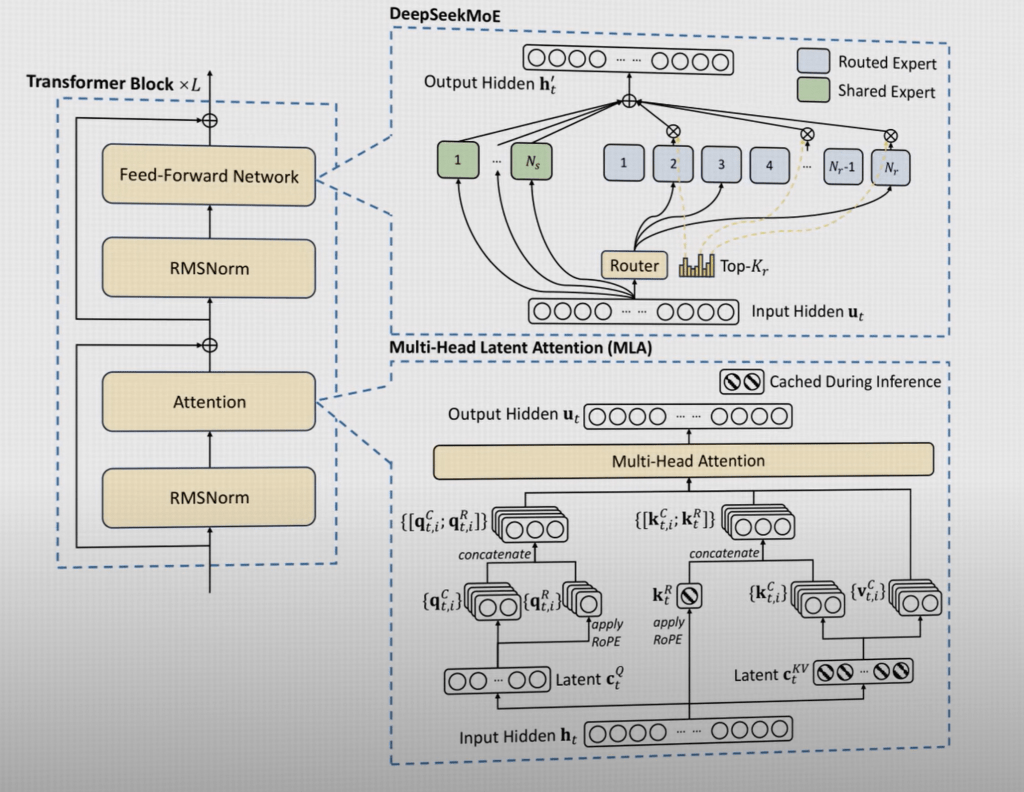
Another innovation is MoE, mixture of experts and MLA, multi-head latent attention, which reduce the k, v cache size by 93%.

Third, multi-token prediction, MTP:

Both openAI and deepseek realize powerful reasoning ability by reinforcement learning RL. But how did they do it? it’s GRPO.